
线性代数(上册)
本文从线性变换出发理解线性代数的本质

机器学习(V)--无监督学习(五)异常检测
异常检测
远离其它内围点(inlier)的数据通常被定义为离群值(outlier),也称异常值。异常检测(anomaly detection)分为离群点检测以及新奇值检测两种。
Outlier D ...
机器学习(V)--无监督学习(七)核密度估计
核密度估计
核密度估计(kernel density estimate,kde):是一种用于估计概率密度函数的非参数方法,可看作直方图的拟合曲线。
我们知道,对概率密度函数(Probability ...

机器学习(II)--数据预处理
有这么一句话在业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。由此可见,特征工程在机器学习中占有相当重要的地位。在实际应用当中,可以说特征工程是机器学习成功的关键。
...

机器学习(I)--基础知识
前言
机器学习 (machine learning, ML)的主要目的是设计和分析一些学习算法,让计算机可以从数据(经验)中自动分析并获得规律,之后利用学习到的规律对未知数据进行预测,从而帮助人们完 ...
机器学习(I)--参数估计
参数估计
事实上,概率模型的训练过程就是参数估计(parameter estimation)过程。对于参数估计,统计学界的两个学派分别提供了不同的解决方案:
频率主义学派(Frequentist) ...
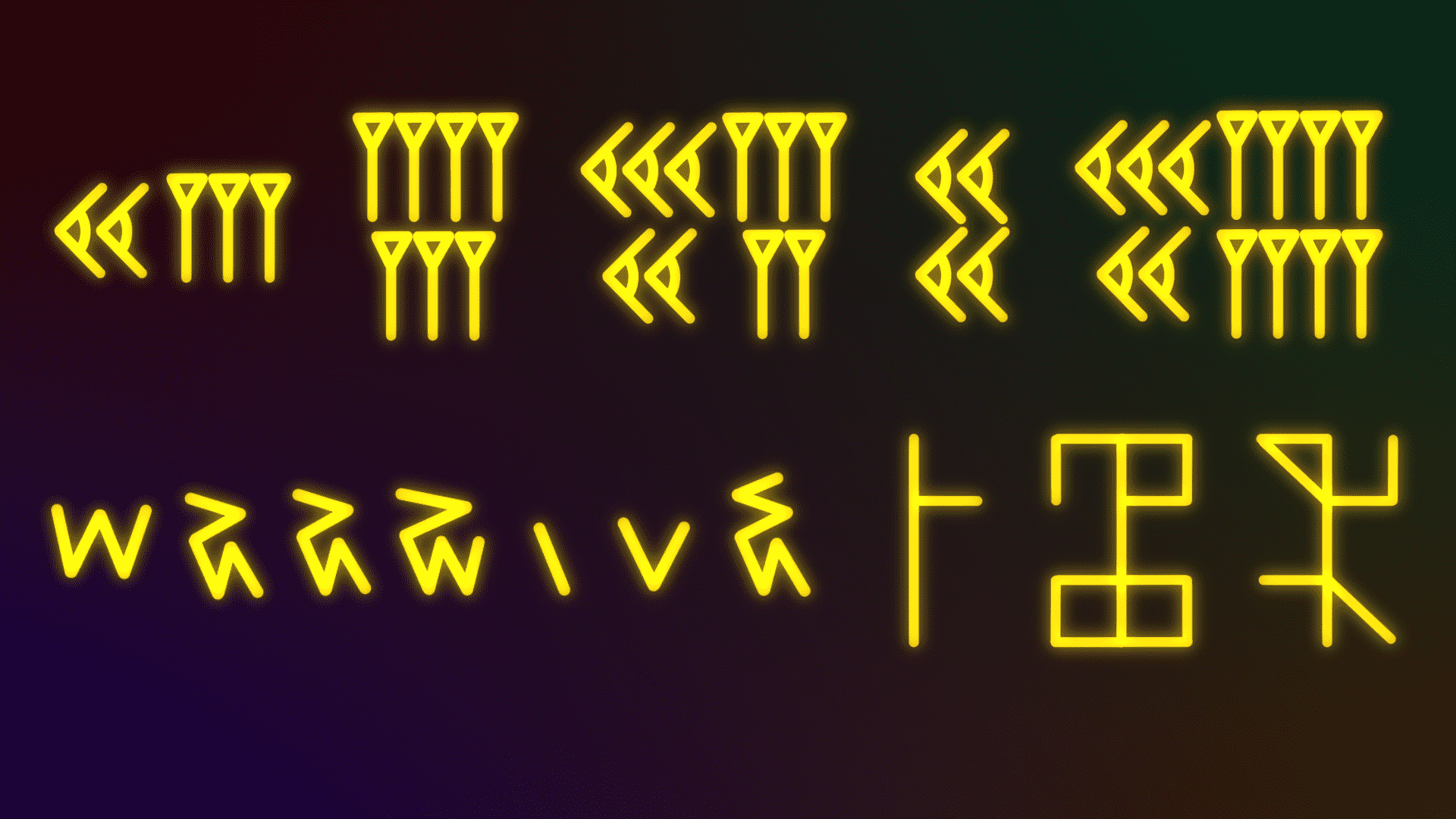
看不懂的数字
之前看了一期李永乐老师的视频,介绍了一些奇怪的数字系统,觉得蛮有意思的,就决定记下来了。
10分钟学会写别人看不懂的数字!你又能跟小伙伴炫耀了! - 李永乐
Arabic numerals
Arab ...

机器学习(IV)--监督学习(一)线性回归
每个样本都有标签的机器学习称为监督学习。根据标签数值类型的不同,监督学习又可以分为回归问题和分类问题。分类和回归是监督学习的核心问题。
回归(regression)问题中的标签是连续值。
分类(cl ...
机器学习(IV)--监督学习(二)线性分类
每个样本都有标签的机器学习称为监督学习。根据标签数值类型的不同,监督学习又可以分为回归问题和分类问题。分类和回归是监督学习的核心问题。
回归(regression)问题中的标签是连续值。
分类(cl ...

机器学习(III)--模型选择与评估
模型选择
经验风险最小化
机器学习基本概括为通过数据、模型、代价函数、优化来建立一个算法。模型的假设空间包含所有可能的映射函数,例如线性函数集合。接下来要考虑按照什么样的准则来学习或者优化模型,我 ...




