Spark Streaming 是利用 Spark Core 的快速计划功能执行流式分析的实时解决方案。它会提取迷你批处理中的数据,使用为批处理分析编写的相同应用程序代码实现对此类数据的分析。这样一来,开发人员的效率得到改善,因为他们可以将相同代码用于批处理和实时流式处理应用程序。Spark Streaming 支持来自 Twitter、Kafka、Flume、HDFS 和 ZeroMQ 的数据,以及 Spark 程序包生态系统中的其他众多数据。
Spark Streaming
概述
Hadoop的MapReduce及Spark SQL等只能进行离线计算,无法满足实时性要求较高的业务需求,例如实时推荐、实时网站性能分析等,流式计算可以解决这些问题。目前有三种比较常用的流式计算框架,它们分别是Twitter Storm,Spark Streaming和Samza。
Spark Streaming用于进行实时流数据的处理,它具有高扩展、高吞吐率及容错机制。
如下图所示,Spark Streaming 把流式计算当做一系列连续的小规模批处理(batch)来对待。Spark Streaming 接收输入数据流,并在内部将数据流按均匀的时间间隔分为多个较小的batch。然后再将这部分数据交由Spark引擎进行处理,处理完成后将结果输出到外部文件。
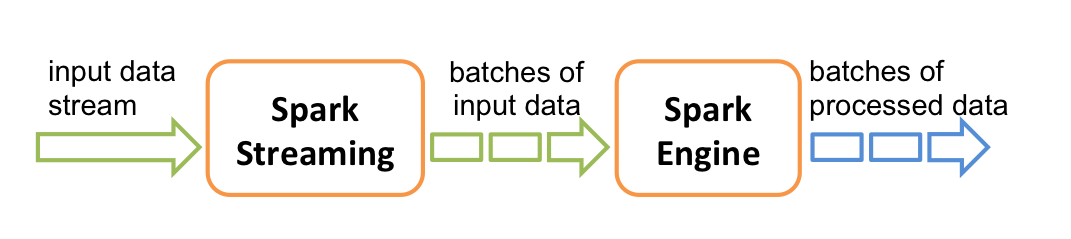
Spark Streaming的主要抽象是离散流(DStream),它代表了前面提到的构成数据流的那些batch。DStream可以看作是多个有序的RDD组成,因此它也只通过map, reduce, join and window等操作便可完成实时数据处理。,另外一个非常重要的点便是,Spark Streaming可以与Spark MLlib、Graphx等结合起来使用,功能十分强大,似乎无所不能。
目前,围绕Spark Streaming有四种广泛的场景:
- streaming ETL:将数据推入下游系统之前对其进行持续的清洗和聚合。这么做通常可以减少最终数据存储中的数据量。
- Triggers(触发器):实时检测行为或异常事件,及时触发下游动作。例如当一个设备接近了检测器或者基地,就会触发警报。
- 数据浓缩:将实时数据与其他数据集连接,可以进行更丰富的分析。例如将实时天气信息与航班信息结合,以建立更好的旅行警报。
- 复杂会话和持续学习:与实时流相关联的多组事件被持续分析,以更新机器学习模型。例如与在线游戏相关联的用户活动流,允许我们更好地做用户分类。
下图提供了Spark driver、workers、streaming源与目标间的数据流:

Spark Streaming内置了一系列receiver,可以接收很多来源的数据,最常见的是Apache Kafka、Flume、HDFS/S3、Kinesis和Twitter。
应用案例及数据源
Spark Streaming可整合多种输入数据源,如Kafka、Flume、HDFS,甚至是普通的TCP套接字。经处理后的数据可存储至文件系统、数据库,或显示在仪表盘里。

编写Spark Streaming程序的基本步骤是:
- 通过创建输入DStream来定义输入源
- 通过对DStream应用转换操作和输出操作来定义流计算
- 用streamingContext.start()来开始接收数据和处理流程
- 通过streamingContext.awaitTermination()方法来等待结束(例如<ctrl+C>),或通过streamingContext.stop()来手动结束流计算进程
下面我们使用Python的Spark Streaming来创建一个简单的单词计数例子。
这个字数计数示例将使用Linux/Unix nc命令——它是一种读写跨网络连接数据的简单实用程序。我们将使用两个不同的bash终端,一个使用nc命令将多个单词发送到我们计算机的本地端口(9999),另一个终端将运行Spark Streaming来接收这些字,并对它们进行计数。
#!/usr/bin/env python3 |
如前所述,现在有了脚本,打开两个终端窗口:一个用于您的nc命令,另一个用于Spark Streaming程序。
要从其中一个终端启动nc命令,请键入:
$ nc -lk 9999 |
从这个点开始,你在这个终端所输入的一切都将被传送到9999端口。本例中,敲入green这个词三次,blue五次。
从另一个终端屏幕,我们来运行刚创建的Python流脚本(NetworkWordCount.py)。
$ spark-submit NetworkWordCount.py localhost 9999 |
该命令将运行脚本,读取本地计算机(即localhost)端口9999以接收发送到该套接字的任何内容。由于你已经在第一个终端将信息发送端口,因此在启动脚本后不久,Spark Streaming程序会读取发送到端口9999的任何单词,并按照以下屏幕截图中所示的样子执行单词计数:
$ nc -lk 9999 |
文件流:包括文本格式和任意HDFS的输入格式。创建DStream输入源示例
lines = ssc.textFileStream('wordfile') |
套接字流 (socket):从一个本地或远程主机的某个端口服务上读取数据。它无法提供端到端的容错保障,Socket源一般仅用于测试或学习用途。

创建DStream输入源示例
lines = ssc.socketTextStream("local", 9999) |
RDD序列流:在调试Spark Streaming应用程序的时候,我们可以使用streamingContext.queueStream(queueOfRDD)创建基于RDD队列的DStream
kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
在公司的大数据生态系统中,可以把Kafka作为数据交换枢纽,不同类型的分布式系统(关系数据库、NoSQL数据库、流处理系统、批处理系统等),可以统一接入到Kafka,实现和Hadoop各个组件之间的不同类型数据的实时高效交换。
下图为kafka组成

- Broker:Kafka集群包含一个或多个服务器,这种服务器被称为broker
- Topic :每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
- Partition:是物理上的概念,每个Topic包含一个或多个Partition.
- Producer:负责发布消息到Kafka broker
- Consumer:消息消费者,向Kafka broker读取消息的客户端。
- Consumer Group:每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)


我们可以创建基于Kafka的DStream
from pyspark.streaming.kafka import KafkaUtils |
转化操作
无状态转化操作:把简单的RDDtransformation分别应用到每个批次上,每个批次的处理不依赖于之前的批次的数据。
![]()
有状态转化操作:需要使用之前批次的数据或者中间结果来计算当前批次的数据。包括基于滑动窗口的转化操作,和追踪状态变化的转化操作(updateStateByKey)

| 无状态转化操作 | 说明(同RDD转化类似) |
|---|---|
map(func) |
映射变换 |
flatMap(func) |
同RDD |
filter(func) |
返回过滤后新的DStream |
reduce(func) |
聚合 |
count() |
计数 |
union(otherStream) |
合并 |
countByValue() |
值计数 |
reduceByKey(func, [numTasks]) |
对于相同key的数据聚合 |
join(otherStream, [numTasks]) |
交集 |
cogroup(otherStream, [numTasks]) |
|
transform(func) |
任意变换 |
repartition(numPartitions) |
重分区 |
滑动窗口转化操作
window(windowLength, slideInterval) 基于源DStream产生的窗口化的批数据,计算得到一个新的Dstream
countByWindow(windowLength, slideInterval) 返回流中元素的一个滑动窗口数
reduceByWindow(func, windowLength, slideInterval) 返回一个单元素流。利用函数func聚集滑动时间间隔的流的元素创建这个单元素流。函数func必须满足结合律,从而可以支持并行计算
countByValueAndWindow(windowLength, slideInterval, [numTasks]) 当应用到一个(K,V)键值对组成的DStream上,返回一个由(K,V)键值对组成的新的DStream。每个key的值都是它们在滑动窗口中出现的频率
reduceByKeyAndWindow方法
reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) 应用到一个(K,V)键值对组成的DStream上时,会返回一个由(K,V)键值对组成的新的DStream。每一个key的值均由给定的reduce函数(func函数)进行聚合计算。注意:在默认情况下,这个算子利用了Spark默认的并发任务数去分组。可以通过numTasks参数的设置来指定不同的任务数。
reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) 更加高效的reduceByKeyAndWindow,每个窗口的reduce值,是基于先前窗口的reduce值进行增量计算得到的;它会对进入滑动窗口的新数据进行reduce操作,并对离开窗口的老数据进行“逆向reduce”操作。但是,只能用于“可逆reduce函数”,即那些reduce函数都有一个对应的“逆向reduce函数”(以InvFunc参数传入)。

lines = ssc.socketTextStream("localhost", 9999) |
UpdateStateByKey转化方法:需要在跨批次之间维护状态时,需要UpdateStateByKey方法。通俗点说,假如我们想知道一个用户最近访问的10个页面是什么,可以把键设置为用户ID,然后UpdateStateByKey就可以跟踪每个用户最近访问的10个页面,这个列表就是“状态”对象。
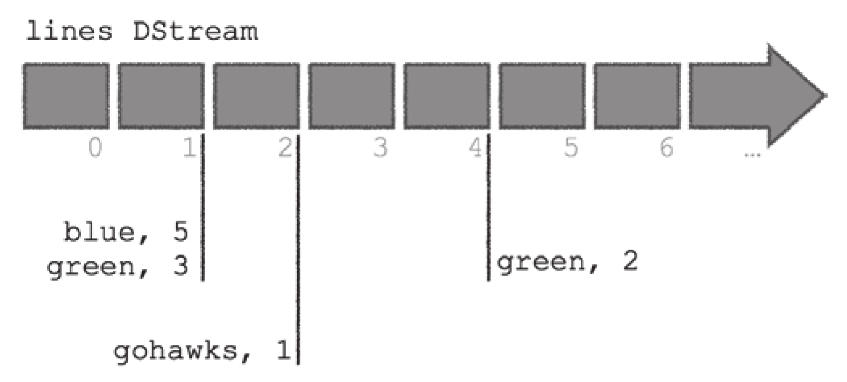
回到本章初的应用案例(无状态转化),1秒在nc端键入3个green和5个blue,2秒再键入1个gohawks,4秒再键入2个green。
下图展示了lines DStream及其微批量数据:
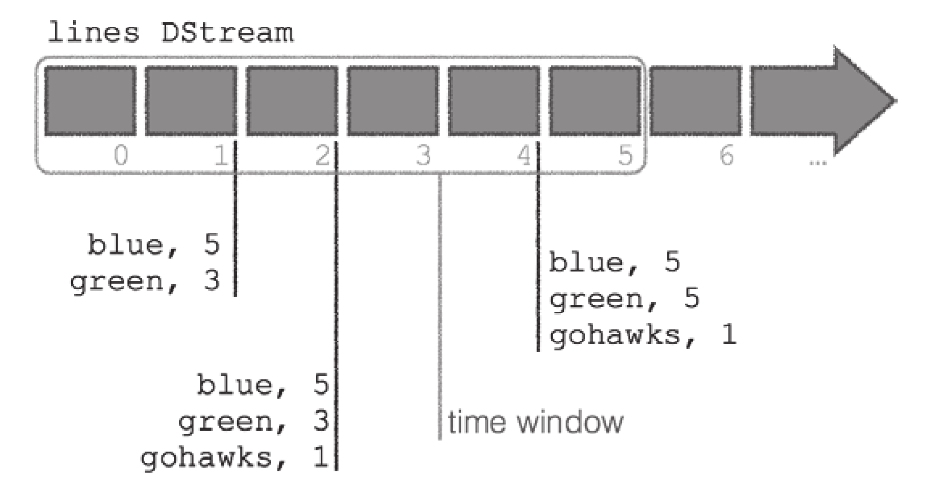
下图表示我们计算的是有状态的全局聚合:
代码如下
#!/usr/bin/env python3 |
两者的主要区别在于使用了updateStateByKey方法,该方法将执行前面提到的执行加和的updateFunc。updateStateByKey是Spark Streaming的方法,用于对数据流执行计算,并以有利于性能的方式更新每个key的状态。通常在Spark 1.5及更早版本中使用updateStateByKey,这些有状态的全局聚合的性能与状态的大小成比例,从Spark 1.6起,应该使用mapWithState。
Structured Streaming
概述
对于Spark 2.0,Apache Spark社区致力于通过引入结构化流(structured streaming)的概念来简化流,结构化流将Streaming概念与Dataset/DataFrame相结合。结构化流式引入的是增量,当处理一系列数据块时,结构化流不断地将执行计划应用在所接收的每个新数据块集合上。通过这种运行方式,引擎可以充分利用Spark DataFrame/Dataset所包含的优化功能,并将其应用于传入的数据流。

- 微批处理:Structured Streaming默认使用微批处理执行模型,这意味着Spark流计算引擎会定期检查流数据源,并对自上一批次结束后到达的新数据执行批量查询。(数据到达和得到处理并输出结果之间的延时超过100毫秒)
- 持续处理:Spark从2.3.0版本开始引入了持续处理的试验性功能,可以实现流计算的毫秒级延迟。
在持续处理模式下,Spark不再根据触发器来周期性启动任务,而是启动一系列的连续读取、处理和写入结果的长时间运行的任务。
应用案例及数据源
编写Structured Streaming程序的基本步骤包括:
- 创建输入数据源
- 定义流计算过程
- 启动流计算并输出结果
我们来看一下使用updateStateByKey的有状态流的文字计数脚本,并将其改成一个Structured Streaming的文字计数脚本:

#!/usr/bin/env python3 |
取而代之的,流那部分的代码是通过调用readStream来初始化的,我们可以使用熟悉的DataFrame groupBy语句和count来生成运行的文字计数。
由于程序中需要用到拆分字符串和展开数组内的所有单词的功能,所以引用了来自pyspark.sql.functions里面的split和explode函数。
让我们回到第一个终端运行我们的nc作业:
$ nc -lk 9999 |
检查以下输出。如你所见,你既能得到有状态流的优势,还能使用更为熟悉的DataFrame API:
------------------------------------------- |
数据流:通过调用readStream来初始化。支持的格式包括文件流(csv、json、orc、parquet、text)、Kafka、套接字流(socket)、Rate源等。
lines = spark \ |
输出:DataFrame/Dataset的.writeStream()方法将会返回DataStreamWriter接口,接口通过.start()真正启动流计算,并将DataFrame/Dataset写入到外部的输出接收器,DataStreamWriter接口有以下几个主要函数:
- format:接收器类型。
- outputMode:输出模式,指定写入接收器的内容,可以是Append模式、Complete模式或Update模式。
- queryName:查询的名称,可选,用于标识查询的唯一名称。
- trigger:触发间隔,可选,设定触发间隔,如果未指定,则系统将在上一次处理完成后立即检查新数据的可用性。如果由于先前的处理尚未完成导致超过触发间隔,则系统将在处理完成后立即触发新的查询。
输出模式用于指定写入接收器的内容,主要有以下几种:
- Append模式:只有结果表中自上次触发间隔后增加的新行,才会被写入外部存储器。这种模式一般适用于“不希望更改结果表中现有行的内容”的使用场景。
- Complete模式:已更新的完整的结果表可被写入外部存储器。
- Update模式:只有自上次触发间隔后结果表中发生更新的行,才会被写入外部存储器。这种模式与Complete模式相比,输出较少,如果结果表的部分行没有更新,则不会输出任何内容。当查询不包括聚合时,这个模式等同于Append模式。
query = windowedCounts \ |
参考链接:
- Spark 编程基础 - 厦门大学 | 林子雨
- Learning PySpark - Tomasz Drabas
- Give me money!










