tidyverse是一系列包的组合,构建了一套完整的数据分析生态链,提供了一套整洁的数据导入,分析和建模方法,刷新了R语言原有的数据科学体系。
tidyverse
Usage
- small, in-memory data ( <2Gb): tidyverse
- larger data (10-100 Gb): data.table
- Parallel computing : need a system (like Hadoop or Spark)
core tidyverse packages
tidyverse_packages() #查看tidyverse内含的包 |
library(tidyverse) will load the core tidyverse packages:
- ggplot2, for data visualisation.
- dplyr, for data manipulation.
- tidyr, for data tidying.
- readr, for data import.
- purrr, for functional programming.(FP)
- tibble, for tibbles, a modern re-imagining of data frames.
Import
As well as readr, for reading flat files, the tidyverse includes:
- readxl for .xls and .xlsx sheets.
- feather, for sharing with Python and other languages.
- haven for SPSS, Stata, and SAS data.
- jsonlite for JSON.
- xml2 for XML.
- httr for web APIs.
- rvest for web scraping.
- DBI for relational databases.
Wrangle
As well as tidyr, and dplyr, there are five packages designed to work with specific types of data:
- stringr for strings.
- lubridate for dates and date-times.
- forcats for categorical variables (factors).
- hms for time-of-day values.
- blob for storing blob (binary) data.
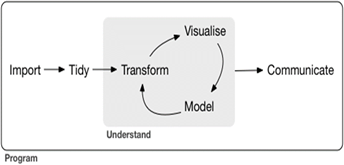
Program
除了purrr处理函数式编程外,还有三个解决常规编程的包
- rlang 提供了R的核心语言和tidyverse的工具
- magrittr 管道函数
- glue 提供了base::paste()的更加丰富的版本
Model
- modelr, for modelling within a pipeline
- broom, for turning models into tidy data
 Give me money!
Give me money!

相关推荐






评论




