Introduction
mlr 提供机器学习的统一接口:tasks, learners, hyperparameters, etc
- Tasks:建立任务,包括任务描述(classification, regression, clustering, etc)和数据集
- Learners:建立学习者,指定机器学习算法(GLM, SVM, xgboost, etc)和参数
- Hyperparameters:对Learners直接指定超参数或超参数调优。给Learners一个可能的参数集列表。
- Wrapped Models:已封装模型,已经被训练可以预测的模型
- Predictions:应用模型到新数据或者原始数据进行预测
- Meastures:模型评估指标(RMSE, logloss, AUC, etc)
- Resampling:重抽样,通过分离训练集来拟合通用的模型,通常包括holdout 验证,K折交叉验证(K-fold cross-validation),留一交叉验证(LOOCV)
Workflow
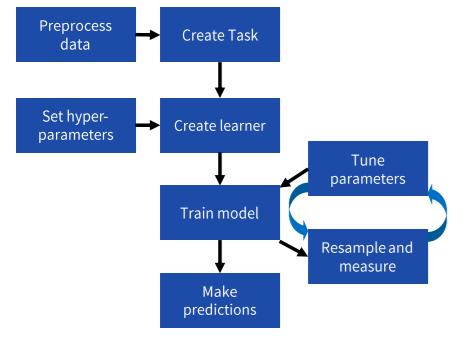
Preprocessing data (预处理)
| 函数 | 说明 |
|---|---|
| createDummyFeatures(obj=,target=,method=,cols=) | 为每一个非数值变量创建哑变量(0,1),不包括目标变量target,也可以指定变量cols |
| normalizeFeatures(obj=,target=,method=,cols=, range=,on.constant=) | 数字变量标准化,method: {“center”, “scale”,“standardize”,“range”(default range=c(0,1)) } |
| mergeSmallFactorLevels(task=,cols=,min.perc=) | 组合进单一的factor level |
| summarizeColumns(obj=) | data.frame or Task的汇总说明 |
| capLargeValues(obj,cols=NULL) | 离群值转化(帽子法) |
| dropFeatures | |
| removeConstantFeatures | |
| summarizeLevels |
Task and Learner
Create a task
| 创建任务 | 说明 |
|---|---|
| makeClassifTask(data=,target=) | 回归问题 |
| makeRegrTask(data=,target=) | 分类,目标列必须是一个factor |
| makeMultilabelTask(data=,target=) | 多标签分类问题,每个对象可以同时属于多个类别 |
| makeClusterTask(data=) | 聚类分析 |
| makeSurvTask(data=,target=c(“time”,“event”)) | 生存分析 |
| makeCostSensTask(data=,costs=) | 成本敏感的分类,分类中的标准目标是获得较高的预测准确度,即最小化分类器产生的错误数量 |
| getTaskDesc(x) | 获得总的任务描述,查看positiv |
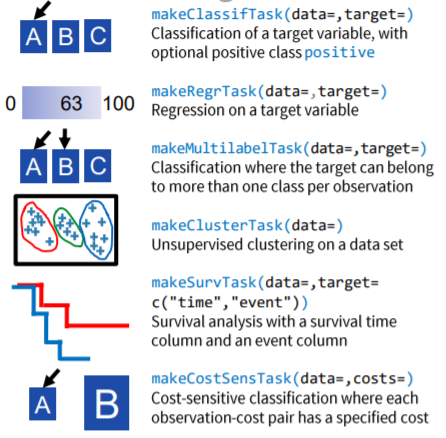
task的其他参数:
- weight:将权重向量应用到记录
- block:传递因子向量将记录绑定到一块,重抽样的时候不会 被拆分
Making a learner
makeLearner(cl,predict.type = "response",predict.threshold = NULL, ...,par.vals)指定机器学习算法,也能一次指定多个
参数:
- cl:指定要使用的算法名,cl=
<task_Type>.<R_method_name>(“classif.xgboost”,
“regr.randomForest” ,“cluster.kmeans”,etc) - predict.type:"response"返回原始数据,"prob"返回分类问题的概率,"se"返回回归问题的标准误
- par.vals:传递超参数列表,也能直接传递(…)
- predict.threshold :生成类标签的阈值
mlr有超过170个不同的是算法:mlr已经集成的算法
- listLearners():展示所有的learner
- listLearners(task):task允许的所有learner
- listLearners(“classif”,properties=c(“prob”, “factors”)):展示所有的分类问题中,能输出概率"prob",和因子“factors”
- See also getLearnerProperties()
Training & Testing (训练和测试)
Setting hyperparameters (设置超参数)
setHyperPars(learner=,...)传递超参数给learner
getParamSet(learner=)获得learner可能的超参数文本(such as “classif.qda”)
Train a model and predict (训练模型和预测)
train(learner, task,subset)训练模型,subset设置训练集(默认是全部数据)
getLearnerModel(model)将底层的学习者模型纳入mlr
predict(model,task,subset)预测原始数据
predict(model,newdata)预测新数据
as.data.frame(pred)查看预测的结果
pred2<- setThreshold(pred, threshold)重设分类问题的阈值,重新预测
Measuring performance (模型评估质量)
performance(pred=,measures=) 依照一个或几个指标评估模型
getDefaultMeasure(task/learner)查看默认指标
listMeasures()查看完整的指标列表
listMeasures(task)查看匹配指标
通过参数measures=list(mse,medse,mae)指定评估指标
- classif: acc auc bac ber brier[.scaled] f1 fdr fn
fnr fp fpr gmean multiclass[.au1u .aunp .aunu
.brier] npv ppv qsr ssr tn tnr tp tpr wkappa - regr: arsq expvar kendalltau mae mape medae
medse mse msle rae rmse rmsle rrse rsq sae
spearmanrho sse - cluster: db dunn G1 G2 silhouette
- multilabel: multilabel[.f1 .subset01 .tpr .ppv
.acc .hamloss] - costsens: mcp meancosts
- surv: cindex
- other: featperc timeboth timepredict timetrain
分类任务的评估详情:
calculateConfusionMatrix(pred)获得混淆矩阵
calculateROCMeasures(pred)ROC曲线
Resampling a learner (重抽样)
makeResampleDesc(method=,...,stratify=)
makeResampleInstance(desc=,task=)确保每次抽样统一,以减少噪声值
| 参数 | 说明 |
|---|---|
| method | 重抽样的方法 |
| “CV” | cross-volidation(交叉验证),用iters指定k-folds(K折)数 |
| “LOO” | leave-one-out cross-volidation(留一交叉验证),用iters指定k-folds数 |
| “RepCV” | repeated cross-volidation(反复交叉验证),reps指定重复数,用iters指定k-folds数 |
| “Subsample” | aka Monte-Carlo cross-volidation ,用iters指定k-folds数,split指定train% |
| “Bootstrap” | out-of-bag bootstrap(袋装法),iters |
| “Holdout” | for train% use split |
| stratify | 保持目标变量的抽样比例 |
resample(learner=,task=,resampling=,measures=)通过指定重抽样训练和测试模型
- mlr有若干预先定义的重抽样:
cv2(2-koldscross-volidation),
cv3, cv5, cv10, hout(holdout with split 2/3 for traing, 1/3 for testing) - 也可以用重抽样函数传递给
resample()
crossval() repcv() holdout() subsample()
bootstrapOOB() bootstrapB632() bootstrapB632plus()
Tuning hyperparameters (超参数调优)
设定超参数搜索空间
makeParamSet(make<type>Param())
make<type>Param() |
指定超参数搜索类型和范围 |
|---|---|
| makeNumericParam(id=,lower=,upper=,trafo=) | 数字 |
| makeIntegerParam(id=,lower=,upper=,trafo=) | 整数 |
| makeIntegerVectorParam(id=,len=,lower=,upper=,trafo=) | 整数向量 |
| makeDiscreteParam(id=,values=c(…)) | 分类变量 |
| Logical, LogicalVector, CharacterVector, DiscreteVector | 其他类型 |
参数trafo可以用一个指定函数转换输出:例如lower=-2,upper=2,trafo=function(x) 10^x,输出值between 0.01 and 100
设定超参数搜索算法
makeTuneControl<type>()
<type> |
说明 |
|---|---|
| Grid(resolution=10L) | 所有可能的网格点 |
| Random(maxit=100) | 随机抽样搜索空间 |
| MBO(budget=) | Bayesion model-based optimization(基于贝叶斯模型的最优化) |
| Irace(n.instances=) | 迭代比赛过程 |
| CMAES() | |
| Design() | |
| GenSA() |
超参数调优
tuneParams(learner=,task=,resampling=,measures=,par.set=,control=)超参数调优函数
Quickstart
# 预处理数据 |
Configuration (配置)
用getMlrOptions()查看mlr 的现有设置
用configureMlr()更改mlr的默认设置
参数:
- show.info:(traning, tuning, resampling,etc)是否展示默认冗长的输出,默认TRUE
- on.learner.error:怎样控制learner的错误, “stop”(default), “warn”, “quiet”
- on.learner.warning:怎样控制learner的警告,“warn”(default) , “quiet”
- on.par.without.desc:超参数控制,“stop”(default), “warn” ,“quiet”
- on.par.out.of.bounds:超参数超出边界值,“stop”(default) ,“warn”, “quiet”
- on.measure.not.applicable:评估指标对learner不适用,“stop”(default) , “warn”, “quiet”
- show.learner.output:learner在训练的时候输出到控制台,默认TRUE
- on.error.dump:是否为crashed learner创建一个error dump,当on.learner.error 没有被指定为"stop" 时,默认TRUE
Parallelization (并行)
mlr结合parallelMap包利用多核和集群运算加快运行速度,mlr自动发现能进行并行的操作。
开始并行:parallelStart(mode=,cpus=,level=)
结束并行:parallelStop()
| 参数 | 说明 |
|---|---|
| mode | 决定并行的方式 |
| “local” | 无并行性,简单的使用mapply |
| “multicore” | 单机器上多核,使用parallel::mclapply,windows上不适用 |
| “socket” | 多核socked mode |
| “mpi” | 一个或多个机器上集群运算,使用parallel::makeCluster and parallel::clusterMap |
| “BatchJobs” | 批排队HPC集群,使用BatchJobs::batchMap |
| cpus | 使用的物理内核数 |
| level | 控制并行,使用"mlr.benchmark" “mlr.resample” “mlr.selectFeatures” “mlr.tuneParams” “mlr.ensemble” |
Imputation (插补)
impute(obj=,target=,cols=,dummy.cols=,dummy.type=)
缺失的数据进行插补,返回一个列表,包括插补过额数据集或task,和插补描述
reimpute(obj=,desc=)用已被impute创建的插补描述(description, desc)插补缺失值
- obj= data.frame or task
- target= 指定目标变量,将不会被插补
- cols= 要插补的列名或逻辑列表
- dummy.cols= 建立NA(T/F)列的列名
- dummy.type= 设定"numeric",用(0,1)代替(T/F)
- 也能用classes 和dummy.classes 代替cols
传递给cols或classes的list示例:
cols=list(V1=imputeMean()) V1是要插补的列,imputeMean()为要插补的方法
| 允许的插补方法 | 说明 |
|---|---|
| imputeConst(const=) | 常数 |
| imputeMedian() | 中位数 |
| imputeMode() | 众数 |
| imputeMin(multiplier=) | 最小值 |
| imputeMax(multiplier=) | 最大值 |
| imputeNormal(mean=,sd=) | 正态插补 |
| imputeHist(breaks=,use.mids=) | |
| imputeLearner(learner=,features=) | 模型插补 |
Feature Extraction (特征提取)
Feature filtering(特征筛选)

filterFeatures(task=,method=,perc=,abs=,threshold=)
按特征的重要性进行排序,选择其中的top n percent(perc=), top n(abs=) or 设定阈值(threshold=),返回task,没有被筛选的特征将会被删除。
默认的筛选方法为"randomForestSRC.rfsrc",也可以设置其他方法:
“anova.test” “carscore” “cforest.importance”
“chi.squared” “gain.ratio” “information.gain”
“kruskal.test” “linear.correlation” “mrmr” “oneR”
“permutation.importance” “randomForest.importance”
“randomForestSRC.rfsrc” “randomForestSRC.var.select”
“rank.correlation” “relief”
“symmetrical.uncertainty” “univariate.model.score”
“variance”
Feature selection(特征选择)

selectFeatures(learner=,task=, resampling=,measures=,control=)
用一个特征选择算法(control)重抽样和建立模型,反复选择不同的特征集,直到找到最好的特征集。返回FeatSelResult对象,包括最佳选择和最佳路径。
tsk = subsetTask(tsk,features=fsr$x)应用最佳选择结果(fsr)到task(tsk)
特征选择算法(control):
makeFeatSelControlExhaustive(max.features=)尝试每一种特征组合,可选参数max.featuresmakeFeatSelControlRandom(maxit=,prob=,max.features=)随机抽取特征集(概率prob,default 0.5) 迭代(maxit,default 100),返回其中最好的。makeFeatSelControlSequential(method=,maxit=,max.features=,alpha=,beta=)用以下的迭代算法搜寻,评估:
“sfs” forward search, “sffs” floating forward search,
“sbs” backward search , “sfbs” floating backward search,
“alpha” 每次增加一个特征来改善评估,取最少特征集
“beta” 每次移除一个特征来改善评估,取最少特征集makeFeatSelControlGA(maxit=,max.features=,mu=,lambda=,crossover.rate=,mutation.rate=)随机特征向量的遗传算法,然后利用最佳性能的交叉来产生后代,代代相传,参数:
mu是父系规模
lambda 是子系规模
crossover.rate 从第一亲本选择一点的概率
mutation.rate 是翻转的概率(on or off)
Benchmarking (基准点)
benchmark(learners=,tasks=,resamplings=,measures=)
允许进行简单的比较:执行单一task的多重learner,执行多重task的单一learner,或者执行多重task的多重learner,返回一个基准结果对象。
基准结果被函数getBMR<object>接收:
AggrPerformance
FeatSelResults FilteredFeatures LearnerIds
LeanerShortNames Learners MeasureIds Measures
Models Performances Predictions TaskDescs TaskIds
TuneResults
mlr内置了许多有趣的task,对基准学习很有帮助:
agri.task bc.task bh.task costiris.task iris.task
lung.task mtcars.task pid.task sonar.task
wpbc.task yeast.task
Visualization (可视化)
1. 可视化总表
| 生成数据函数 | ggplot2绘图函数 | ggvis绘图函数 | 说明 |
|---|---|---|---|
| generateThreshVsPerfData | plotThresVsPerf | plotThreshVsPerfGGVIS | 性能 |
| plotROCCurves | - | ROC分析 | |
| generateCritDifferencesData | plotCritDifferences | - | 基准实验 |
| generateHyperParsEffectData | plotHyperParsEffect | 调整,超参数调整效果 | |
| generateFilterValuesData | plotFilterValues | plotFilterValuesGGVIS | 功能选择 |
| generateLearningCurveData | plotLearningCurve | plotLearningCurveGGVIS | 学习曲线 |
| generatePartialDependenceData | plotPartialDependence | plotPartialDependenceGGVIS | 部分依赖情节 |
| generateFunctionalANOVAData | |||
| generateCalibrationData | plotCalibration | - | 分类器校准图 |
2. 可视化函数说明
| Performance | 表现 |
|---|---|
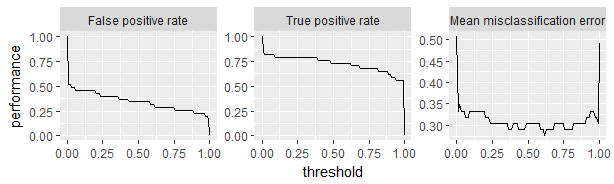
| generateThreshVsPerfData(obj=,measures=) | 获得二分类问题不同切分点评估质量,促使选出最优阈值(threshold) |
| plotThreshVsPerf(obj) | 用ThreshVsPerfData数据作出阈值可视化表现 |
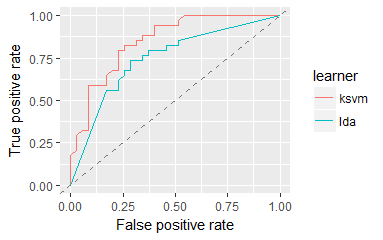
| plotROCCurves(obj) | 用ThreshVsPerfData数据做出ROC曲线,一定要设定measures=list(fpr,tpr) |
| Residuals | 残差 |
| plotResiduals(obj=) | 为Prediction 或BenchmarkResult对象作残差 |
示例
n = getTaskSize(sonar.task) |
| Learning curve | 学习曲线 |
|---|---|
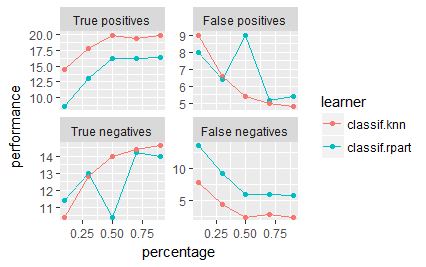
| generateLearningCurveData(learners=,task=,resampling=,percs=,measures=) | 获得不同百分比的task data上做模型评估质量数据 |
| plotLearningCurve(obj) | 比较数据的已使用和模型质量的关系,使用LearningCurveData对象 |
示例
r = generateLearningCurveData( |
| Feature importance | 特征重要性 |
|---|---|
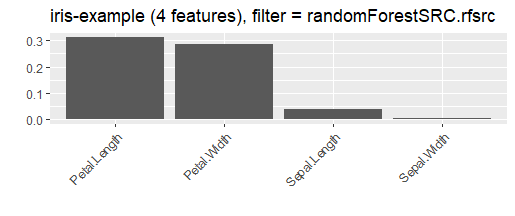
| generateFilterValuesData(task=,method=) | 用指定的选择方法获得排序的特征重要性 |
| plotFilterValues(obj=) | 可视化特征重要性,FilterValuesData对象 |
示例
fv = generateFilterValuesData(iris.task) |
| Hyperparameters tuning | 超参数调优 |
|---|---|
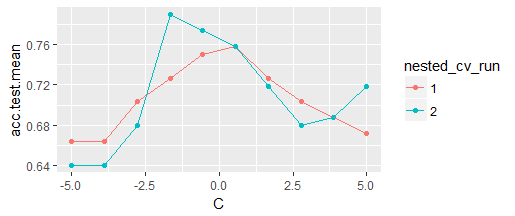
| generateHyperParsEffectData(tune.result=) | 获得不同超参数的影响 |
| plotHyperParsEffect(hyperpars.effect.data=,x=,y=,z=) | 可视化超参数影响,HyperParsEffectData对象 |
| plotOptPath(op=) | 可视化最优进程详情,<obj>$opt.path对象, <obj>是 tuneResult或 featSelResult类的对象。 |
| plotTuneMultiCritResult(res=) | 展示pareto图,多重评估质量的调优结果 |
示例
ps = makeParamSet( |
| Partial dependence | 部分依赖 |
|---|---|
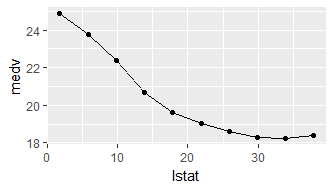
| generatePartialDependenceData(obj=,input=) | 获得模型(obj)的部分依赖预测,通过每一次的特征数据输入(input) |
| plotPartialDependence(obj=) | 部分依赖图,PartialDependenceData对象 |
示例
lrn.regr = makeLearner("regr.ksvm") |
| Benchmarking | 基准点 |
|---|---|
| plotBMRBoxplots(bmr=) | 表现的分类图 |
| plotBMRSummary(bmr=) | 平均表现的散点图 |
| plotBMRRanksAsBarChart(bmr=) | learner 排序柱形图 |
| Other | 其他图 |
|---|---|
| generateCritDifferencesData(bmr=,measure=,p.value=,test=) | 执行临界差检验,用bonforroni-dunn(“bd”) 或"Nemenyi"检验 |
| plotCritDifferences(obj=) | 临界点检验可视化 |
| generateCalibrationData(obj=) | 评估概率预测与真实发生率的校准 |
| plotCalibration(obj=) | 校准图 |

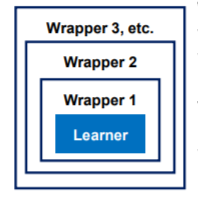
Wrappers (封装器)
封装器使具有附加功能的学习者融合。mlr把带有封装器的learner看作一个单独的learner,超参数的封装也会与基础模型参数联合调谐。带包装的模型将应用于新数据。
| Preprocessing and imputation | 预处理和插补 |
|---|---|
| makeDummyFeaturesWrapper(learner=) | |
| makeImputeWrapper(learner=,classes=,cols=) | |
| makePreprocWrapper(learner=,train=,predict=) | |
| makePreprocWrapperCaret(learner=,…) | |
| makeRemoveConstantFeaturesWrapper(learner=) | |
| Class imbance | 类别不平衡 |
| makeOverBaggingWrapper(learner=) | |
| makeSMOTEWrapper(learner=) | |
| makeUndersampleWrapper(learner=) | |
| makeWeightedClassesWrapper(learner=) | |
| Cost-sensitive | 成本分析 |
| makeCostSensClassifWrapper(learner=) | |
| makeCostSensRegrWrapper(learner=) | |
| makeCostSensWeightedPairsWrapper(learner=) | |
| Multilabel classification | 多标签分类 |
| makeMultilabelBinaryRelevanceWrapper(learner=) | |
| makeMultilabelClassifierChainsWrapper(learner=) | |
| makeMultilabelDBRWrapper(learner=) | |
| makeMultilabelNestedStackingWrapper(learner=) | |
| makeMultilabelStackingWrapper(learner=) | |
| Other | 其他 |
| makeBaggingWrapper(learner=) | |
| makeConstantClassWrapper(learner=) | |
| makeDownsampleWrapper(learner=,dw.perc=) | |
| makeFeatSelWrapper(learner=,resampling=,control=) | |
| makeFilterWrapper(learner=,fw.perc=,fw.abs=,fw.threshold=) | |
| makeMultiClassWrapper(learner=) | |
| makeTuneWrapper(learner=,resampling=,par.set=,control=) |
Nested Resampling (嵌套重采样)
mlr支持嵌套重采样进行复杂操作,例如通过包装来调优和特征选择等。为了获得良好的泛化性能估计和避免数据泄漏,建议使用外部(用于调优/特征选择)和内部(对于基本模型)重采样过程。
- 外部重采样能在resample, benchmark中被指定
- 内部重采样能在makeTuneWrapper, makeFeatSelWrapper, etc中被指定
Ensembles (集成)
makeStackedLearner(base.learners=,super.learner=,method=)将多重learner集成
参数:
- base.learners= 使用初始预测的learners
- super.learner= 使用最终预测的learners
- method= 组合base learners预测的方法
“average”:所有base learners的平均
“stack.nocv” “stack.cv”:在base learners的结果上训练super learner (with or without cross-validation)
“hill.climb”:搜索最优权重平均
“compress”:用神经网络实现更快的性能
 Give me money!
Give me money!











