Scikit-learn是一个开源机器学习库,支持监督和非监督学习。它还为模型拟合、数据预处理、模型选择、模型评估和许多其他实用程序提供了各种工具。
Scikit-learn提供数十种内置的机器学习算法和模型,称为 estimator (估计器)。估计器是任何从数据中学习的对象;它可能是分类、回归或聚类算法,也可能是从原始数据中提取/过滤有用特征的。每个估计器都可以使用 fit 方法拟合数据,然后使用 predict 方法预测或使用transform方法转化数据。
Scikit-Learn
分类:SVM、近邻、随机森林、逻辑回归等等。
回归:Lasso、岭回归等等。
聚类:k-均值、谱聚类等等。
降维:PCA、特征选择、矩阵分解等等。
选型:网格搜索、交叉验证、度量。
预处理:特征提取、标准化。
The simplest sklearn workflow
以下是一个简单的示例,以 GradientBoostingClassifier 为例,简述下sklearn建模流程:
Jupyter Notebook Demo
Step 1: 加载数据集
from sklearn.datasets import load_digitsfrom sklearn.model_selection import train_test_splitX, y = load_digits(n_class = 2 , return_X_y = True ) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3 )
Step 2: 拟合模型
from sklearn.ensemble import GradientBoostingClassifierclf = GradientBoostingClassifier() clf.fit(X_train,y_train) clf.get_params()
Step 3: 模型评估
Step 4: 模型保存和导入
from sklearn.externals import joblibjoblib.dump(clf, 'GBDT.pkl' ) clf = joblib.load('GBDT.pkl' )
Step 5: 模型预测
y_pred = clf.predict(X_test) y_prob = clf.predict_proba(X_test) y_pred = bst.predict(X_test).argmax(1 )
内置数据集
说明
load_iris
鸢尾花数据集(150x4),常用于分类任务
load_boston
波士顿房价预测,常用于回归任务示例
load_digits
手写数字预测(1797x64),常用于神经网络
>>> from sklearn.datasets import load_iris, load_digits>>> data = load_iris()>>> data.target[[10 , 25 , 50 ]]array([0 , 0 , 1 ]) >>> list (data.target_names)['setosa' , 'versicolor' , 'virginica' ] >>> X, y = load_digits(n_class=2 , return_X_y=True )
创建数据集
说明
make_classification
生成分类数据集
make_blobs
生成分类数据集,有更大的灵活性
make_multilabel_classification
生成带有多个标签的分类数据
make_regression
生成回归数据集
make_circles
生成2d分类数据集,两个球面
make_moons
生成2d分类数据集,两个交错半圆
常用参数:
n_samples:指定样本数
n_features:指定特征数
n_classes:分类问题类的数量
n_informative:有效特征数量
n_redundant:冗余特征数量
n_repeated:重复特征数量
n_clusters_per_class:每个类的集群数量
coef:bool,否返回线性模型的系数
random_state:随机数
>>> from sklearn.datasets import make_classification, make_regression >>> from sklearn.datasets import make_classification >>> X, y = make_classification(random_state=42) >>> X.shape (100, 20) >>> y.shape (100,) >>> list(y[:5]) [0, 0, 1, 1, 0]
from sklearn.model_selection import train_test_split
常用参数:
test_size:float,样本比例,默认0.25;int,样本量
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25 )
import picklewith open ('model.pickle' ,'wb' ) as f: pickle.dumps(model,f) with open ('model.pickle' ,'rb' ) as f: clf = pickle.loads(f) from sklearn.externals import joblibjoblib.dump(model, 'model.pkl' ) model = joblib.load('model.pkl' )
sklearn.linear_model
线性模型
LinearRegression
普通最小二乘法
Ridge
岭回归
Lasso
估计稀疏系数的线性模型回归
MultiTaskLasso
多任务 Lasso 回归
LogisticRegression
logistic 回归
SGDRegressor
随机梯度下降回归
SGDClassifier
随机梯度下降分类
ElasticNetCV
弹性网络回归
MultiTaskElasticNet
多任务弹性网络回归
>>> from sklearn.kernel_ridge import KernelRidge>>> import numpy as np>>> n_samples, n_features = 10 , 5 >>> rng = np.random.RandomState(0 )>>> y = rng.randn(n_samples)>>> X = rng.randn(n_samples, n_features)>>> krr = KernelRidge(alpha=1.0 )>>> krr.fit(X, y)KernelRidge(alpha=1.0 )
sklearn.svm
支持向量机
SVC
支持向量机分类
SVR
支持向量机回归
sklearn.neighbors
最近邻算法
NearestNeighbors
无监督最近邻
KNeighborsClassifier
k-近邻分类
RadiusNeighborsClassifier
固定半径近邻分类
KNeighborsRegressor
最近邻回归
RadiusNeighborsRegressor
NearestCentroid
最近质心分类
sklearn.gaussian_process
高斯过程
GaussianProcessRegressor
高斯过程回归(GPR)
GaussianProcessClassifier
高斯过程分类(GPC)
Kernel
高斯过程内核
sklearn.tree
决策树
DecisionTreeClassifier
决策树分类
DecisionTreeRegressor
决策树回归
sklearn.kernel_ridge
内核岭回归
KernelRidge
内核岭回归
sklearn.isotonic.IsotonicRegression
等式回归
IsotonicRegression
sklearn.multiclass
多类多标签算法
multiclass
sklearn.naive_bayes
朴素贝叶斯分类器
GaussianNB
高斯朴素贝叶斯
MultinomialNB
多项分布朴素贝叶斯
BernoulliNB
伯努利朴素贝叶斯
sklearn.ensemble
集成方法
BaggingClassifier
Bagging分类
BaggingRegressor
Bagging回归
RandomForestClassifier
随机森林分类
RandomForestRegressor
随机森林回归
ExtraTreesClassifier
极限随机树分类
ExtraTreesRegressor
极限随机树回归
AdaBoostClassifier
AdaBoost分类
AdaBoostRegressor
AdaBoost回归
GradientBoostingClassifier
梯度树提升分类
GradientBoostingRegressor
梯度树提升回归
HistGradientBoostingClassifier
梯度树提升分类
HistGradientBoostingRegressor
梯度树提升回归
VotingClassifier
投票分类器
VotingRegressor
投票回归器
StackingClassifier
堆叠范化
StackingRegressor
堆叠范化
>>> from sklearn import datasets>>> from sklearn.model_selection import cross_val_score>>> from sklearn.linear_model import LogisticRegression>>> from sklearn.naive_bayes import GaussianNB>>> from sklearn.ensemble import RandomForestClassifier>>> from sklearn.ensemble import VotingClassifier>>> iris = datasets.load_iris()>>> X, y = iris.data[:, 1 :3 ], iris.target>>> clf1 = LogisticRegression(random_state=1 )>>> clf2 = RandomForestClassifier(n_estimators=50 , random_state=1 )>>> clf3 = GaussianNB()>>> eclf = VotingClassifier(... estimators=[('lr' , clf1), ('rf' , clf2), ('gnb' , clf3)],... voting='hard' )>>> for clf, label in zip ([clf1, clf2, clf3, eclf], ['Logistic Regression' , 'Random Forest' , 'naive Bayes' , 'Ensemble' ]):... scores = cross_val_score(clf, X, y, scoring='accuracy' , cv=5 )... print ("Accuracy: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), label))Accuracy: 0.95 (+/- 0.04 ) [Logistic Regression] Accuracy: 0.94 (+/- 0.04 ) [Random Forest] Accuracy: 0.91 (+/- 0.04 ) [naive Bayes] Accuracy: 0.95 (+/- 0.04 ) [Ensemble]
堆叠算法
>>> from sklearn.linear_model import RidgeCV, LassoCV>>> from sklearn.neighbors import KNeighborsRegressor>>> estimators = [('ridge' , RidgeCV()),... ('lasso' , LassoCV(random_state=42 )),... ('knr' , KNeighborsRegressor(n_neighbors=20 ,... metric='euclidean' ))]>>> from sklearn.ensemble import GradientBoostingRegressor>>> from sklearn.ensemble import StackingRegressor>>> final_estimator = GradientBoostingRegressor(... n_estimators=25 , subsample=0.5 , min_samples_leaf=25 , max_features=1 ,... random_state=42 )>>> reg = StackingRegressor(... estimators=estimators,... final_estimator=final_estimator)
sklearn.neural_network
神经网络
MLPClassifier
多层感知器(MLP)分类
MLPRegressor
多层感知器(MLP)回归
sklearn.mixture
高斯混合模型
GaussianMixture
高斯混合
BayesianGaussianMixture
变分贝叶斯高斯混合
sklearn.cluster
聚类
KMeans
K-means聚类
AffinityPropagation
AP聚类
MeanShift
SpectralClustering
AgglomerativeClustering
层次聚类
DBSCAN
Birch
>>> from sklearn.cluster import MiniBatchKMeans>>> import numpy as np>>> X = np.array([[1 , 2 ], [1 , 4 ], [1 , 0 ],... [4 , 2 ], [4 , 0 ], [4 , 4 ],... [4 , 5 ], [0 , 1 ], [2 , 2 ],... [3 , 2 ], [5 , 5 ], [1 , -1 ]])>>> >>> kmeans = MiniBatchKMeans(n_clusters=2 ,... random_state=0 ,... batch_size=6 ,... n_init="auto" )>>> kmeans = kmeans.partial_fit(X[0 :6 ,:])>>> kmeans = kmeans.partial_fit(X[6 :12 ,:])>>> kmeans.cluster_centers_array([[3.375 , 3. ], [0.75 , 0.5 ]]) >>> kmeans.predict([[0 , 0 ], [4 , 4 ]])array([1 , 0 ], dtype=int32) >>> >>> kmeans = MiniBatchKMeans(n_clusters=2 ,... random_state=0 ,... batch_size=6 ,... max_iter=10 ,... n_init="auto" ).fit(X)>>> kmeans.cluster_centers_array([[3.55102041 , 2.48979592 ], [1.06896552 , 1. ]]) >>> kmeans.predict([[0 , 0 ], [4 , 4 ]])array([1 , 0 ], dtype=int32)
sklearn.cluster.bicluster 双聚类
SpectralCoclustering
SpectralBiclustering
sklearn.decomposition
矩阵分解
PCA
准确的主成分分析和概率解释
IncrementalPCA
增量主成分分析
KernelPCA
核主成分分析
SparsePCA
稀疏主成分分析
MiniBatchSparsePCA
小批量稀疏主成分分析
TruncatedSVD
截断奇异值分解
SparseCoder
带有预计算词典的稀疏编码
DictionaryLearning
通用词典学习
MiniBatchDictionaryLearning
小批量字典学习
FactorAnalysis
高斯分布因子分析
FastICA
隐变量基于非高斯分布因子分析
FastICA
独立成分分析
NMF
非负矩阵分解
LatentDirichletAllocation
隐 Dirichlet 分配(LDA)
>>> from sklearn.datasets import load_digits>>> from sklearn.decomposition import IncrementalPCA>>> from scipy import sparse>>> X, _ = load_digits(return_X_y=True )>>> transformer = IncrementalPCA(n_components=7 , batch_size=200 )>>> >>> transformer.partial_fit(X[:100 , :])IncrementalPCA(batch_size=200 , n_components=7 ) >>> >>> X_sparse = sparse.csr_matrix(X)>>> X_transformed = transformer.fit_transform(X_sparse)>>> X_transformed.shape(1797 , 7 )
sklearn.manifold
流形学习,是一种非线性降维方法
Isomap
等距映射(Isometric Mapping)
LocallyLinearEmbedding
局部线性嵌入
SpectralEmbedding
谱嵌入
MDS
多维尺度分析
TSNE
t 分布随机邻域嵌入(t-SNE)
sklearn.metrics
Description
accuracy_score(y_true, y_pred)
分类:准确率
balanced_accuracy_score(y_true, y_pred)
分类:平衡准确率
f1_score(y_true, y_pred)
分类:f1 score
precision_score(y_true, y_pred)
分类:精准率
average_precision_score(y_true, y_pred)
分类:平均精准率
log_loss(y_true, y_pred)
分类:损失
roc_auc_score(y_true, y_score)
分类:auc值(ROC曲线下面积)
recall_score(y_true, y_pred)
分类:召回率
confusion_matrix(y_true, y_pred)
分类:混淆矩阵
explained_variance_score(y_true, y_pred)
回归:可解释方差
mean_absolute_error(y_true, y_pred)
回归:MAE
mean_squared_error(y_true, y_pred)
回归:均方误差(MSE)
root_mean_squared_error(y_true, y_pred)
回归:均方标准差(RMSE)
r2_score(y_true, y_pred)
回归:R2
label_ranking_loss
排序度量
adjusted_mutual_info_score
聚类:互信息
completeness_score
聚类:完整性
homogeneity_score
聚类:同质性
示例:
>>> import numpy as np>>> from sklearn.metrics import accuracy_score>>> y_pred = [0 , 2 , 1 , 3 ]>>> y_true = [0 , 1 , 2 , 3 ]>>> accuracy_score(y_true, y_pred)0.5 >>> accuracy_score(y_true, y_pred, normalize=False )2.0
混淆矩阵:
>>> y_true = [0 , 0 , 0 , 1 , 1 , 1 , 1 , 1 ]>>> y_pred = [0 , 1 , 0 , 1 , 0 , 1 , 0 , 1 ]>>> confusion_matrix(y_true, y_pred, normalize='all' )array([[0.25 , 0.125 ], [0.25 , 0.375 ]]) >>> tn, fp, fn, tp = confusion_matrix(y_true, y_pred).ravel()>>> tn, fp, fn, tp(2 , 1 , 2 , 3 )
分类报告:
>>> from sklearn.metrics import classification_report>>> y_true = [0 , 1 , 2 , 2 , 0 ]>>> y_pred = [0 , 0 , 2 , 1 , 0 ]>>> target_names = ['class 0' , 'class 1' , 'class 2' ]>>> print (classification_report(y_true, y_pred, target_names=target_names)) precision recall f1-score support class 0 0.67 1.00 0.80 2 class 1 0.00 0.00 0.00 1 class 2 1.00 0.50 0.67 2 accuracy 0.60 5 macro avg 0.56 0.50 0.49 5 weighted avg 0.67 0.60 0.59 5
从二分类到多分类多标签
一些指标基本上是为二进制分类任务定义的(例如 f1_score,roc_auc_score),这些情况下,只评估正类,默认情况下正类被标记为 1(当然也可以通过 pos_label 参数配置)。
在将二分类度量扩展到多类或多标签问题时,数据被视为二分类问题的集合。在可用的情况下,应该使用average参数从下面选择计算方法。
"macro"简单地计算二分类度量的平均值,给每个类同等权重"weighted" 计算每个类分数的加权平均值,权重由数据样本权重得到"micro"在多标签任务中,微平均可能是首选"samples"仅适用于多标签问题选择average=None将返回一个包含每个类分数的数组
>>> from sklearn import metrics>>> y_true = [0 , 1 , 2 , 0 , 1 , 2 ]>>> y_pred = [0 , 2 , 1 , 0 , 0 , 1 ]>>> metrics.precision_score(y_true, y_pred, labels=[0 , 1 , 2 , 3 ], average='macro' )0.166 ...
单指标评估
scores = cross_val_score(estimator, X, y=None , scoring=None , cv=None )
常用参数:
scoring:评分函数或sklearn预定义的评分字符串
cv:交叉验证(Cross-validation)数量
return:包含所有的结果的 ndarray
>>> from sklearn import svm, datasets>>> from sklearn.model_selection import cross_val_score>>> X, y = datasets.load_iris(return_X_y=True )>>> clf = svm.SVC(random_state=0 )>>> cross_val_score(clf, X, y, cv=5 , scoring='recall_macro' )array([0.96 ..., 0.96 ..., 0.96 ..., 0.93 ..., 1. ])
Note:如果传递了错误的评分名称,则会引发InvalidParameterError。您可以通过调用get_scorer_names来检索所有可用度量的名称。
多指标评估
Scikit-learn还允许在GridSearchCV、RandomizedSearchCV和cross_validate中评估多个指标。
scores = cross_validate(estimator, X, y=None , scoring=None , cv=None )
常用参数:
scoring:str, callable, list, tuple, or dict
cv:交叉验证(Cross-validation)数量
return:包含所有的结果的 dict
>>> cv_results = cross_validate(lasso, X, y, cv=3 )>>> sorted (cv_results.keys())['fit_time' , 'score_time' , 'test_score' ] >>> cv_results['test_score' ]array([0.3315057 , 0.08022103 , 0.03531816 ])
多个指标可以指定为列表、元组或一组预定义的记分器名称:
>>> scoring = ['accuracy' , 'precision' ]
或者作为dict映射记分器名称到预定义或自定义记分函数:
>>> from sklearn.metrics import make_scorer>>> scoring = {'prec_macro' : 'precision_macro' ,... 'rec_macro' : make_scorer(recall_score, average='macro' )}
Receiver operating characteristic (ROC)
>>> import numpy as np>>> from sklearn.metrics import roc_curve>>> y = np.array([1 , 1 , 2 , 2 ])>>> scores = np.array([0.1 , 0.4 , 0.35 , 0.8 ])>>> fpr, tpr, thresholds = roc_curve(y, scores, pos_label=2 )>>> fprarray([0. , 0. , 0.5 , 0.5 , 1. ]) >>> tprarray([0. , 0.5 , 0.5 , 1. , 1. ]) >>> thresholdsarray([ inf, 0.8 , 0.4 , 0.35 , 0.1 ])
>>> import matplotlib.pyplot as plt>>> from sklearn.datasets import load_diabetes>>> from sklearn.linear_model import Ridge>>> from sklearn.metrics import PredictionErrorDisplay>>> X, y = load_diabetes(return_X_y=True )>>> ridge = Ridge().fit(X, y)>>> y_pred = ridge.predict(X)>>> display = PredictionErrorDisplay(y_true=y, y_pred=y_pred)>>> display.plot()<...> >>> plt.show()
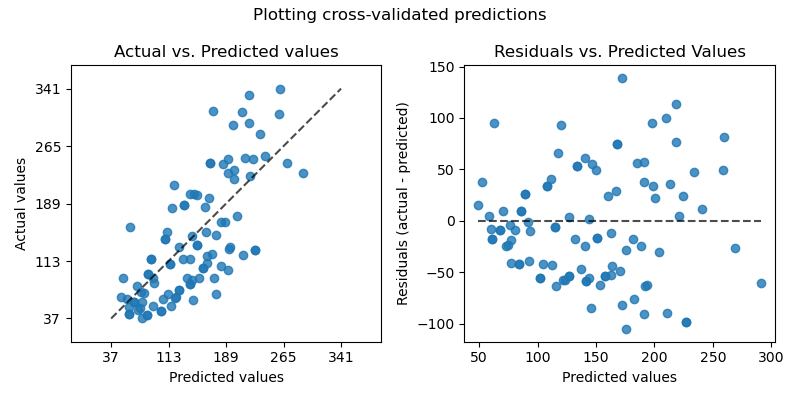
当拟合线性最小二乘回归模型时(LinearRegression和Ridge),我们可以使用此图来检查是否满足一些模型假设,特别是残差应不相关,其期望值应为零,其方差应为常数。
绘制得分曲线以评估模型
>>> import numpy as np>>> from sklearn.model_selection import validation_curve>>> from sklearn.svm import SVC>>> train_scores, valid_scores = validation_curve(... SVC(kernel="linear" ), X, y, ... param_name="C" , ... param_range=np.logspace(-7 , 3 , 3 ), ... cv=None , scoring=None )>>> train_scoresarray([[0.90 ..., 0.94 ..., 0.91 ..., 0.89 ..., 0.92 ...], [0.9 ... , 0.92 ..., 0.93 ..., 0.92 ..., 0.93 ...], [0.97 ..., 1. .. , 0.98 ..., 0.97 ..., 0.99 ...]]) >>> valid_scoresarray([[0.9 ..., 0.9 ... , 0.9 ... , 0.96 ..., 0.9 ... ], [0.9 ..., 0.83 ..., 0.96 ..., 0.96 ..., 0.93 ...], [1. ... , 0.93 ..., 1. ... , 1. ... , 0.9 ... ]])
如果训练分数和验证分数都很低,模型将不合适。如果训练分数高,验证分数低,则模型过拟合,否则效果很好。
可以使用 validation_curve 的 from_estimator 方法来只绘制验证曲线:
>>> from sklearn.model_selection import ValidationCurveDisplay>>> ValidationCurveDisplay.from_estimator( SVC(kernel="linear" ), X, y, param_name="C" , param_range=np.logspace(-7 , 3 , 10 ) )
学习曲线显示了不同数量的训练样本的估计器的验证和训练分数。可以让我们了解从添加更多训练数据中获益多少,以及估算器是否因方差误差或偏差误差而造成更多损失。
可以使用函数learning_curve来生成绘制此类学习曲线所需的值:
>>> from sklearn.model_selection import learning_curve>>> from sklearn.svm import SVC>>> train_sizes, train_scores, valid_scores = learning_curve(... SVC(kernel='linear' ), X, y, train_sizes=[50 , 80 , 110 ], cv=5 )>>> train_sizesarray([ 50 , 80 , 110 ]) >>> train_scoresarray([[0.98 ..., 0.98 , 0.98 ..., 0.98 ..., 0.98 ...], [0.98 ..., 1. , 0.98 ..., 0.98 ..., 0.98 ...], [0.98 ..., 1. , 0.98 ..., 0.98 ..., 0.99 ...]]) >>> valid_scoresarray([[1. , 0.93 ..., 1. , 1. , 0.96 ...], [1. , 0.96 ..., 1. , 1. , 0.96 ...], [1. , 0.96 ..., 1. , 1. , 0.96 ...]])
可以使用LearningCurveDisplay的from_estimator方法来只绘制学习曲线
>>> from sklearn.model_selection import LearningCurveDisplay>>> LearningCurveDisplay.from_estimator( SVC(kernel="linear" ), X, y, train_sizes=[50 , 80 , 110 ], cv=5 )
超参数是估计器中没有直接学习的参数。在scikit-learn中,它们作为参数传递给估计器类的构造函数。建议在超参数空间中搜索最佳交叉验证分数进行优化。要获得估计器所有参数的名称和当前值,请使用:
目前来说sklearn中超参数优化器有四种:
sklearn.model_selection
模型选择
GridSearchCV
网格搜索详尽地考虑了所有参数组合
RandomizedSearchCV
随机搜索可以从具有指定分布的参数空间中抽样给定数量的候选者
HalvingGridSearchCV
对半网格搜索
HalvingRandomSearchCV
对半随机网格搜索
其中,对半网格搜索采用了类似锦标赛的筛选机制进行多轮的参数搜索,每一轮输入原始数据一部分数据进行模型训练,并且剔除一半的备选超参数。由于每一轮都只输入了一部分数据,因此不同备选超参数组的评估可能存在一定的误差,但由于每一轮都只剔除一半的超参数组而不是直接选出最优的超参数组,因此也拥有一定的容错性。不难发现,这个过程也像极了RFE过程——每一轮用一个精度不是最高的模型剔除一个最不重要的特征,即保证了执行效率、同时又保证了执行精度。
GridSearchCV 将评估所有可能的参数值组合,并保留最佳组合。
GridSearchCV(estimator, param_grid, scoring=None , cv=None , verbose=0 )
常用参数:
estimator:估计器
param_grid:参数 dict or list of dict
verbose:日志冗长度,int:冗长度,0:不输出训练过程,1:偶尔输出,>1:对每个子模型都输出。
scoring:控制评分,见 sklearn.metrics
常用方法
说明
fit(X, y)
拟合所有参数
get_params()
获得估计器的参数
predict(X)
调用最优参数估计器的predict方法
predict_proba(X)
调用最优参数估计器的predict_proba方法
transform(X)
调用最优参数估计器的transform方法
常用属性
说明
cv_results_
dict of numpy (masked) ndarrays
best_params_
最优参数
best_estimator_
最优估计器
best_score_
最优得分
Examples:
>>> from sklearn import svm, datasets>>> from sklearn.model_selection import GridSearchCV>>> iris = datasets.load_iris()>>> parameters = {'kernel' :('linear' , 'rbf' ), 'C' :[1 , 10 ]}>>> svc = svm.SVC()>>> clf = GridSearchCV(svc, parameters)>>> clf.fit(iris.data, iris.target)GridSearchCV(estimator=SVC(), param_grid={'C' : [1 , 10 ], 'kernel' : ('linear' , 'rbf' )})
首先需要明确的是,参数空间内总备选参数组合的数量为各参数取值之积,且随着参数空间内每个参数取值增加而呈现指数级上升,且随着参数空间内参数维度增加(增加新的超参数)呈指数级上升,且二者呈现叠加效应。
我们可以通过“小步迭代快速调整”的方法来进行超参数的搜索。在这个策略里,我们每次需要设置一个相对较小的参数搜索空间,然后快速执行一次超参数搜索,并根据超参数搜索结果来调整参数空间,并进行更进一步的超参数搜索,如此往复,直到参数空间内包含了全部参数的最优解为止。
RandomizedSearchCV(estimator, param_grid, n_iter=10 , scoring=None , cv=None , verbose=0 )
常用参数:
param_grid:参数 dict or list
verbose:日志冗长度,int:冗长度,0:不输出训练过程,1:偶尔输出,>1:对每个子模型都输出。
scoring:控制评分,见 sklearn.metrics
n_iter:参数指定计算预算,即抽样候选数或抽样迭代的数量。
常用方法
说明
fit(X, y)
拟合所有参数
get_params()
获得估计器的参数
predict(X)
调用最优参数估计器的predict方法
predict_proba(X)
调用最优参数估计器的predict_proba方法
transform(X)
调用最优参数估计器的transform方法
常用属性
说明
cv_results_
dict of numpy (masked) ndarrays
best_params_
最优参数
best_estimator_
最优估计器
best_score_
最优得分
Examples:
>>> from sklearn.datasets import load_iris>>> from sklearn.linear_model import LogisticRegression>>> from sklearn.model_selection import RandomizedSearchCV>>> from scipy.stats import uniform>>> iris = load_iris()>>> logistic = LogisticRegression(solver='saga' , tol=1e-2 , max_iter=200 ,... random_state=0 )>>> distributions = dict (C=uniform(loc=0 , scale=4 ),... penalty=['l2' , 'l1' ])>>> clf = RandomizedSearchCV(logistic, distributions, random_state=0 )>>> search = clf.fit(iris.data, iris.target)>>> search.best_params_{'C' : 2. .., 'penalty' : 'l1' }
Scikit-learn还提供了HalvingGridSearchCV和HalvingRandomSearchCV估计器,可用于使用连续减半搜索参数空间。
HalvingGridSearchCV(estimator, param_distributions, cv=5 , scoring=None , verbose=0 ) HalvingRandomSearchCV(estimator, param_distributions, cv=5 , scoring=None , verbose=0 )
>>> from sklearn.datasets import make_classification>>> from sklearn.ensemble import RandomForestClassifier>>> from sklearn.experimental import enable_halving_search_cv >>> from sklearn.model_selection import HalvingGridSearchCV>>> import pandas as pd>>> >>> param_grid = {'max_depth' : [3 , 5 , 10 ],... 'min_samples_split' : [2 , 5 , 10 ]}>>> base_estimator = RandomForestClassifier(random_state=0 )>>> X, y = make_classification(n_samples=1000 , random_state=0 )>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5 ,... factor=2 , resource='n_estimators' ,... max_resources=30 ).fit(X, y)>>> sh.best_estimator_RandomForestClassifier(max_depth=5 , n_estimators=24 , random_state=0 )
scikit-learn 提供了数据清洗、特征变换、特征提取、特征生成的数据处理估计器。
这些估计器通过fit方法从训练集学习模型参数(例如标准化的平均值和标准差),然后通过transform方法转换数据。fit_transform方法可以同时训练和转换数据,更方便、更有效。
sklearn 目前已经支持 get_feature_names 方法获取转换后的特征名
特征提取被用于将原始特征提取成机器学习算法支持的数据格式,比如文本和图像特征提取。
sklearn.feature_extraction
特征提取
DictVectorizer
从字典加载特征
FeatureHasher
特征hashing技术
text.CountVectorizer
文本特征向量化
text.TfidfTransformer
将文本计数矩阵归一化为TF-IDF矩阵
text.TfidfVectorizer
将原始文档提取为TF-IDF特征
text.HashingVectorizer
大型文本文档的hash向量化
image.extract_patches_2d
将2D图像reshape成分块集合(patches)
image.grid_to_graph
像素到像素连接的图形
image.img_to_graph
像素到像素t梯度连接的图形
image.reconstruct_from_patches_2d
从patches重建图像
image.PatchExtractor
从图像集合中提取patches
从字典加载特征
>>> measurements = [... {'city' : 'Dubai' , 'temperature' : 33. },... {'city' : 'London' , 'temperature' : 12. },... {'city' : 'San Francisco' , 'temperature' : 18. },... ]>>> from sklearn.feature_extraction import DictVectorizer>>> vec = DictVectorizer()>>> vec.fit_transform(measurements).toarray()array([[ 1. , 0. , 0. , 33. ], [ 0. , 1. , 0. , 12. ], [ 0. , 0. , 1. , 18. ]]) >>> vec.get_feature_names_out()array(['city=Dubai' , 'city=London' , 'city=San Francisco' , 'temperature' ], ...)
文本特征向量化
>>> from sklearn.feature_extraction.text import CountVectorizer
>>> from sklearn.feature_extraction.text import CountVectorizer>>> vectorizer = CountVectorizer()>>> corpus = [... 'This is the first document.' ,... 'This is the second second document.' ,... 'And the third one.' ,... 'Is this the first document?' ,... ]>>> X = vectorizer.fit_transform(corpus)>>> vectorizer.get_feature_names_out()array(['and' , 'document' , 'first' , 'is' , 'one' , 'second' , 'the' , 'third' , 'this' ], ...) >>> X.toarray()array([[0 , 1 , 1 , 1 , 0 , 0 , 1 , 0 , 1 ], [0 , 1 , 0 , 1 , 0 , 2 , 1 , 0 , 1 ], [1 , 0 , 0 , 0 , 1 , 0 , 1 , 1 , 0 ], [0 , 1 , 1 , 1 , 0 , 0 , 1 , 0 , 1 ]]...)
sklearn.preprocessing
预处理
StandardScaler()
z-score标准化
Normalizer(norm=‘l2’)
使用l1、l2或max范数归一化
MinMaxScaler()
min-max归一化
MaxAbsScaler()
Max-abs归一化,缩放稀疏数据的推荐方法
RobustScaler()
分位数归一化,缩放有离群值的数据
>>> from sklearn import preprocessing>>> import numpy as np>>> X_train = np.array([[ 1. , -1. , 2. ],... [ 2. , 0. , 0. ],... [ 0. , 1. , -1. ]])>>> scaler = preprocessing.StandardScaler().fit(X_train)>>> scalerStandardScaler() >>> scaler.mean_array([1. ..., 0. ..., 0.33 ...]) >>> scaler.scale_array([0.81 ..., 0.81 ..., 1.24 ...]) >>> X_scaled = scaler.transform(X_train)>>> X_scaledarray([[ 0. ..., -1.22 ..., 1.33 ...], [ 1.22 ..., 0. ..., -0.26 ...], [-1.22 ..., 1.22 ..., -1.06 ...]])
sklearn.preprocessing
预处理
QuantileTransformer
分位数转换,将数据映射到0-1之间的均匀分布,或高斯分布
PowerTransformer
幂变换,将数据从任何分布映射到尽可能接近高斯分布,以稳定方差并最小化倾斜度。
>>> pt = preprocessing.PowerTransformer(method='box-cox' , standardize=False )>>> X_lognormal = np.random.RandomState(616 ).lognormal(size=(3 , 3 ))>>> X_lognormalarray([[1.28 ..., 1.18 ..., 0.84 ...], [0.94 ..., 1.60 ..., 0.38 ...], [1.35 ..., 0.21 ..., 1.09 ...]]) >>> pt.fit_transform(X_lognormal)array([[ 0.49 ..., 0.17 ..., -0.15 ...], [-0.05 ..., 0.58 ..., -0.57 ...], [ 0.69 ..., -0.84 ..., 0.10 ...]])
sklearn.preprocessing
预处理
OrdinalEncoder
编码分类特征
OneHotEncoder
One-hot 编码
LabelEncoder
目标变量重编码
LabelBinarizer
目标标签二值化
MultiLabelBinarizer
多标签目标二值化
常用参数:
categories:每个特征的类别。’auto’ or a list of array-like,
drop=‘if_binary’:删除二分类特征的第一个类别
handle_unknown:’error’, ‘ignore’:忽略未知类别, ‘infrequent_if_exist’:未知类别编码到不频繁类别
min_frequency:生成低频率类别。int or float
max_categories:类别数,可生成低频率类别。
默认情况下,每个特征的取值可以自动从数据集推断,并可以在categories_属性中找到
X = pd.DataFrame([['male' , 'US' , 'Safari' ], ... ['female' , 'Europe' , 'Firefox' ],... ['female' , 'Asia' , 'Chrome' ]],... columns=['gender' , 'location' , 'browser' ])>>> enc = preprocessing.OneHotEncoder()>>> enc.fit_transform(X).toarray()array([[0. , 1. , 0. , 0. , 1. , 0. , 0. , 1. ], [1. , 0. , 0. , 1. , 0. , 0. , 1. , 0. ], [1. , 0. , 1. , 0. , 0. , 1. , 0. , 0. ]]) >>> enc.categories_[array(['female' , 'male' ], dtype=object ), array(['Asia' , 'Europe' , 'US' ], dtype=object ), array(['Chrome' , 'Firefox' , 'Safari' ], dtype=object )]
也可以使用参数categories显式指定类别
>>> genders = ['female' , 'male' ]>>> locations = ['Africa' , 'Asia' , 'Europe' , 'US' ]>>> browsers = ['Chrome' , 'Firefox' , 'IE' , 'Safari' ]>>> enc = preprocessing.OneHotEncoder(categories=[genders, locations, browsers])>>> >>> enc.fit_transform(X).toarray()array([[0. , 1. , 0. , 0. , 0. , 1. , 0. , 0. , 0. , 1. ], [1. , 0. , 0. , 0. , 1. , 0. , 0. , 1. , 0. , 0. ], [1. , 0. , 0. , 1. , 0. , 0. , 1. , 0. , 0. , 0. ]]) >>> enc.categories_[array(['female' , 'male' ], dtype=object ), array(['Africa' , 'Asia' , 'Europe' , 'US' ], dtype=object ), array(['Chrome' , 'Firefox' , 'IE' , 'Safari' ], dtype=object )]
可以使用get_feature_names_out()方法获取列名:
>>> enc.get_feature_names_out()array(['gender_female' , 'gender_male' , 'location_Africa' , 'location_Asia' , 'location_Europe' , 'location_US' , 'browser_Chrome' , 'browser_Firefox' , 'browser_IE' , 'browser_Safari' ], dtype=object )
对于二分类别,OneHotEncoder通过设置参数drop='if_binary'支持保持其中一列
>>> X = [['male' , 'US' , 'Safari' ],... ['female' , 'Europe' , 'Firefox' ],... ['female' , 'Asia' , 'Chrome' ]]>>> drop_enc = preprocessing.OneHotEncoder(drop='if_binary' ).fit(X)>>> drop_enc.categories_[array(['female' , 'male' ], dtype=object ), array(['Asia' , 'Europe' , 'US' ], dtype=object ), array(['Chrome' , 'Firefox' , 'Safari' ], dtype=object )] >>> drop_enc.transform(X).toarray()array([[1. , 0. , 0. , 1. , 0. , 0. , 1. ], [0. , 0. , 1. , 0. , 0. , 1. , 0. ], [0. , 1. , 0. , 0. , 1. , 0. , 0. ]])
OneHotEncoder和OrdinalEncoder支持将不频繁类别的组合到一个类别,能够收集不频繁类别的参数是min_frequency和max_categories。当指定handle_unknown='infrequent_if_exist'时,在转换过程中遇到未知类别时,则被视为不频繁类别,从而不会引发错误。
>>> X = np.array([['dog' ] * 5 + ['cat' ] * 20 + ['rabbit' ] * 10 +... ['snake' ] * 3 ], dtype=object ).T>>> enc = preprocessing.OneHotEncoder(min_frequency=6 , handle_unknown='infrequent_if_exist' )>>> enc.fit(X)OneHotEncoder(handle_unknown='infrequent_if_exist' , min_frequency=6 ) >>> enc.categories_[array(['cat' , 'dog' , 'rabbit' , 'snake' ], dtype=object )] >>> enc.infrequent_categories_[array(['dog' , 'snake' ], dtype=object )] >>> >>> enc.transform([['dog' ], ['cat' ], ['rabbit' ], ['snake' ], ['dragon' ]]).toarray()array([[0. , 0. , 1. ], [1. , 0. , 0. ], [0. , 1. , 0. ], [0. , 0. , 1. ], [0. , 0. , 1. ]])
OneHotEncoder.get_feature_names_out使用 “infrequent_sklearn”作为不频繁的特征的名称:
array(['x0_cat' , 'x0_rabbit' , 'x0_infrequent_sklearn' ], dtype=object )
彩蛋:常用的年龄编码
bins = [0 , 1 , 13 , 20 , 60 , np.inf] labels = ['infant' , 'kid' , 'teen' , 'adult' , 'senior citizen' ]
sklearn.preprocessing
预处理
KBinsDiscretizer
K-bins离散化
Binarizer(threshold=0.0)
二值化
常用参数:
n_bins:分箱数
encode:{‘onehot’, ‘onehot-dense’, ‘ordinal’}, default='onehot’
strategy:定义分箱策略。{‘uniform’, ‘quantile’, ‘kmeans’}, default=‘quantile’
>>> X = np.array([[ -3. , 5. , 15 ],... [ 0. , 6. , 14 ],... [ 6. , 3. , 11 ]])>>> est = preprocessing.KBinsDiscretizer(n_bins=[3 , 2 , 2 ], encode='ordinal' ).fit(X)>>> est.transform(X) array([[ 0. , 1. , 1. ], [ 1. , 1. , 1. ], [ 2. , 0. , 0. ]])
注意:第一个和最后一个分箱边界被扩展到无穷 [-np.inf, bin_edges[1:-1], np.inf]。因此,对于当前示例,这些特征边界被定义为:
feature 1: [ − inf , − 1 ] , [ − 1 , 2 ) , [ 2 , + inf ) [-\inf,-1],[-1,2),[2,+\inf) [ − inf , − 1 ] , [ − 1 , 2 ) , [ 2 , + inf )
feature 2: [ − inf , 5 ] , ( 5 , + inf ) [-\inf,5],(5,+\inf) [ − inf , 5 ] , ( 5 , + inf )
feature 3: [ − inf , 14 ] , ( 14 , + inf ) [-\inf,14],(14,+\inf) [ − inf , 1 4 ] , ( 1 4 , + inf )
sklearn.preprocessing
预处理
PolynomialFeatures(degree=2, interaction_only=False)
生成多项式特征
SplineTransformer(n_knots=5, degree=3, knots=‘uniform’)
生成单变量样条(B-Splines)特征
>>> import numpy as np>>> from sklearn.preprocessing import PolynomialFeatures>>> X = np.arange(6 ).reshape(3 , 2 )>>> Xarray([[0 , 1 ], [2 , 3 ], [4 , 5 ]]) >>> poly = PolynomialFeatures(degree=2 , interaction_only=True )>>> poly.fit_transform(X)array([[ 1. , 0. , 1. , 0. ], [ 1. , 2. , 3. , 6. ], [ 1. , 4. , 5. , 20. ]])
degree=2:X X X ( X 1 , X 2 ) (X_1, X_2) ( X 1 , X 2 ) ( 1 , X 1 , X 2 , X 1 2 , X 1 X 2 , X 2 2 ) (1,X_1,X_2,X_1^2,X_1X_2,X_2^2) ( 1 , X 1 , X 2 , X 1 2 , X 1 X 2 , X 2 2 ) interaction_only=True:只生成交互项 ( 1 , X 1 , X 2 , X 1 X 2 ) (1,X_1,X_2,X_1X_2) ( 1 , X 1 , X 2 , X 1 X 2 )
样条是分段的多项式,由其多项式degree和knots的位置参数控制。
scikit-learn估计器假设数组中的所有值都是数值,且都有意义。
sklearn.impute
缺失值插补
SimpleImputer
单变量插补
IterativeImputer
多重插补
KNNImputer
最近邻插补
MissingIndicator
标记缺失值
SimpleImputer类提供了估算缺失值的基本策略。缺失值可以用提供的常量值估算,也可以使用缺失值所在的每列的统计信息(平均值、中位数或最频繁值)。该类还允许不同的缺失值编码。
常用参数:
missing_values:缺失值的占位符。int, float, str, np.nan, None or pandas.NA , default=np.nan
strategy:估算策略。“mean”, “median”, “most_frequent”, “constant”, default=’mean’
fill_value:str or numerical value, default=None。当 strategy=“constant”,fill_value 用于替换所有出现的 missing_values。
>>> import numpy as np>>> from sklearn.impute import SimpleImputer>>> imp_mean = SimpleImputer(missing_values=np.nan, strategy='mean' )>>> imp_mean.fit([[7 , 2 , 3 ], [4 , np.nan, 6 ], [10 , 5 , 9 ]])SimpleImputer() >>> X = [[np.nan, 2 , 3 ], [4 , np.nan, 6 ], [10 , np.nan, 9 ]]>>> print (imp_mean.transform(X))[[ 7. 2. 3. ] [ 4. 3.5 6. ] [10. 3.5 9. ]]
当使用’most_frequent’或’constant’策略时,SimpleImputer还支持分类数据插补:
>>> import pandas as pd>>> df = pd.DataFrame([["a" , "x" ],... [np.nan, "y" ],... ["a" , np.nan],... ["b" , "y" ]], dtype="category" )... >>> imp = SimpleImputer(strategy="most_frequent" )>>> print (imp.fit_transform(df))[['a' 'x' ] ['a' 'y' ] ['a' 'y' ] ['b' 'y' ]]
更复杂的方法是使用 IterativeImputer类,该类将每个缺失值的特征指定为目标变量y,其他特征列被处理为输入变量X,然后拟合回归模型,用预测值插补缺失值。迭代 max_iter次,返回最后一轮估算的结果。
>>> import numpy as np>>> from sklearn.experimental import enable_iterative_imputer>>> from sklearn.impute import IterativeImputer>>> imp = IterativeImputer(max_iter=10 , random_state=0 )>>> imp.fit([[1 , 2 ], [3 , 6 ], [4 , 8 ], [np.nan, 3 ], [7 , np.nan]])IterativeImputer(random_state=0 ) >>> X_test = [[np.nan, 2 ], [6 , np.nan], [np.nan, 6 ]]>>> >>> print (np.round (imp.transform(X_test)))[[ 1. 2. ] [ 6. 12. ] [ 3. 6. ]]
KNNImputer使用k-Nearest Neighbors方法填充缺失值。默认情况下,使用欧几里得距离查找最近的邻居。每个缺失的值都使用n_neighbors个最近邻的均值填充。
>>> import numpy as np>>> from sklearn.impute import KNNImputer>>> nan = np.nan>>> X = [[1 , 2 , nan], [3 , 4 , 3 ], [nan, 6 , 5 ], [8 , 8 , 7 ]]>>> imputer = KNNImputer(n_neighbors=2 , weights="uniform" )>>> imputer.fit_transform(X)array([[1. , 2. , 4. ], [3. , 4. , 3. ], [5.5 , 6. , 5. ], [8. , 8. , 7. ]])
MissingIndicator 将数据集转换为相应的 bool 矩阵,用来标记缺失值。
>>> from sklearn.impute import MissingIndicator>>> X = np.array([[-1 , -1 , 1 , 3 ],... [4 , -1 , 0 , -1 ],... [8 , -1 , 1 , 0 ]])>>> indicator = MissingIndicator(missing_values=-1 )>>> mask_missing_values_only = indicator.fit_transform(X)>>> mask_missing_values_onlyarray([[ True , True , False ], [False , True , True ], [False , True , False ]])
远离其它内围点(inlier)的数据通常被定义为离群值 (outlier),也称异常值 。异常检测(anomaly detection)分为离群点检测以及新奇值检测两种。
Outlier Detection(OD):离群值检测。训练数据包含异常值,这些异常值被定义为远离其他样本。
Novelty Detection(ND):新奇值检测。训练数据没有异常值,我们检测新样本是否为异常值。在这种情况下,异常值也被称为新奇值。
scikit-learn项目提供了一套无监督学习方法,用于新奇值或异常值检测。
sklearn
说明
svm.OneClassSVM
基于 SVM (使用高斯内核) 的思想在特征空间中训练一个超球面,边界外的点即为异常值。
linear_model.SGDOneClassSVM
基于随机梯度下降(SGD)的One-Class SVM
covariance.EllipticEnvelope
假设数据是高斯分布,训练一个椭圆包络线,边界外的点则为离群点
ensemble.IsolationForest
每次分裂都是随机的,路径长度小的点即为离群点
neighbors.LocalOutlierFactor
局部离群因子。基于密度的异常检测算法
先拟合数据,然后新样本可以使用predict方法分类为内值或外值:内值被标记为1,而异常值被标记为-1。
estimator.fit(X_train) estimator.predict(X_test)
注意:neighbors.LocalOutlierFactor 默认不支持 predict, decision_function and score_samples 方法,仅支持 fit_predict,就像最初被设计检测离群值检测的一样。训练样本的异常值得分可以通过 negative_outlier_factor_ 属性获得。
如果真的想使用neighbors.LocalOutlierFactor进行新奇值检测,可以在拟合估计器之前将novelty参数设置为True来实例化估计器。在这种情况下,fit_predict不可用。请注意,此时必须只对新样本使用predict、decision_function andscore_samples 方法,而不是在训练样本上使用,因为这会导致错误的结果。即predict的结果将与fit_predict不同。训练样本的异常分数仍然可以通过 negative_outlier_factor_属性获得。
Method
Outlier detection
Novelty detection
fit_predictOK
Not available
predictNot available
Use only on new data
decision_functionNot available
Use only on new data
score_samplesUse negative_outlier_factor_
Use only on new data
negative_outlier_factor_OK
OK
>>> import numpy as np>>> from sklearn.neighbors import LocalOutlierFactor>>> X = [[-1.1 ], [0.2 ], [101.1 ], [0.3 ]]>>> clf = LocalOutlierFactor(n_neighbors=2 )>>> clf.fit_predict(X)array([ 1 , 1 , -1 , 1 ]) >>> clf.negative_outlier_factor_array([ -0.9821 ..., -1.0370 ..., -73.3697 ..., -0.9821 ...])
sklearn.feature_selection
特征选择
VarianceThreshold(threshold=0.0)
移除低方差特征,单变量特征选择
SelectKBest(score_func, k=10)
选择 K 个评分最高的特征
SelectPercentile(score_func, percentile=10)
根据最高分数的百分位数选择特征
SelectFpr, SelectFdr, SelectFwe
根据假设检验的p-value选择特征
GenericUnivariateSelect
单变量特征选择估计器汇总
RFECV
在交叉验证中执行递归式特征消除
SelectFromModel
通过特征重要性筛选特征
SequentialFeatureSelector
顺序特征选择
评分函数:
对于回归问题:f_regression , mutual_info_regression, r_regression
对于分类问题:chi2 , f_classif , mutual_info_classif
单变量特征选择通过单变量统计相关性选择最佳特征。
>>> from sklearn.datasets import load_iris>>> from sklearn.feature_selection import SelectKBest>>> from sklearn.feature_selection import f_classif>>> X, y = load_iris(return_X_y=True )>>> X.shape(150 , 4 ) >>> X_new = SelectKBest(f_classif, k=2 ).fit_transform(X, y)>>> X_new.shape(150 , 2 )
递归式特征消除 RFECV 通过特征重要性筛选特征
常用参数:
estimator:具有fit方法的监督学习估计器,通过coef_属性或feature_importances_属性筛选特征
step:int,每次迭代删除的特征数量,float,每次迭代要删除的特征百分比
min_features_to_select:要选择的最小特征数
cv:交叉验证
scoring:评分函数
>>> from sklearn.datasets import make_friedman1>>> from sklearn.feature_selection import RFECV>>> from sklearn.svm import SVR>>> X, y = make_friedman1(n_samples=50 , n_features=10 , random_state=0 )>>> estimator = SVR(kernel="linear" )>>> selector = RFECV(estimator, step=1 , cv=5 )>>> selector = selector.fit(X, y)>>> selector.support_array([ True , True , True , True , True , False , False , False , False , False ]) >>> selector.ranking_array([1 , 1 , 1 , 1 , 1 , 6 , 4 , 3 , 2 , 5 ])
SelectFromModel 通过特征重要性筛选特征
常用参数:
estimator:具有fit方法的监督学习估计器,通过coef_属性或feature_importances_属性筛选特征
threshold:特征选择的阈值,大于阈值的特征将被留下。float,特征百分比,str,“median”, “mean” or “0.1*mean”
min_features_to_select:要选择的最小特征数
SequentialFeatureSelector 按顺序添加(向前选择)或删除(向后选择)特征,以贪婪的方式找出最佳特征子集
常用参数:
estimator:估计器
n_features_to_select:要选择的特征数量。“auto”, int or float, default=”auto”
direction:向前或向后搜索。{‘forward’, ‘backward’}, default=’forward’
scoring:评分。str or callable, default=None
cv:交叉验证
有时,您会希望将现有的Python函数转换为Transformer,以协助数据预处理。FunctionTransformer可以把任意可调用对象构建成一个Transformer。FunctionTransformer将其 X 参数转发到用户定义的函数,并返回此函数的结果。
sklearn.preprocessing.FunctionTransformer(func=None , inverse_func=None , validate=False , accept_sparse=False , check_inverse=True , feature_names_out=None , kw_args=None , inv_kw_args=None )
例如
>>> import pandas as pd>>> import numpy as np>>> from sklearn.preprocessing import FunctionTransformer>>> transformer = FunctionTransformer(pd.get_dummies, kw_args={"dummy_na" :True , "drop_first" :False })>>> X = pd.DataFrame([[0 , 1 ], [2 , 3 ]])>>> >>> transformer.transform(X) 0 1 0 0 1 1 2 3 >>> log_transformer = FunctionTransformer(np.log1p)>>> pipe = make_pipeline(transformer, log_transformer)>>> pipe.transform(X) 0 1 0 0.000000 0.693147 1 1.098612 1.386294
注意:
设置feature_names_out参数后才能启用get_feature_names_out方法。feature_names_out:callable, ‘one-to-one’ or None, default=None
validate参数控制X是否转换为Numpy数组,最好设置validate=True,只有这样才能正常使用feature_names_out参数定义特征名,从而使特征名在管道内正常传输
最好设置accept_sparse=True,可接受稀疏矩阵,避免不必要的报错
>>> X = pd.DataFrame([[0 , 1 ], [2 , 3 ]], columns=['a' , 'b' ])>>> def create_feature_names (self, input_features ):... return input_features>>> transformer = FunctionTransformer(func=lambda x: 2 *x, validate=True , accept_sparse=True , feature_names_out=create_feature_names) >>> enc = OneHotEncoder()>>> pipe = make_pipeline(enc, transformer)>>> pipe.fit_transform(X).toarray()array([[2. , 0. , 2. , 0. ], [0. , 2. , 0. , 2. ]]) >>> pipe.get_feature_names_out()array(['a_0' , 'a_2' , 'b_1' , 'b_3' ], dtype=object )
FunctionTransformer非常方便,但是如果您希望您的转换器是可训练的,在fit()方法中学习一些参数,然后在transform()方法中使用它们。为此,我们需要编写一个自定义类。Scikit-Learn依赖于duck类型,所以这个类不必从任何特定的基类继承。它只需要三个方法:fit()(必须返回self)、transform () 和 fit_transform()。
只需添加TransformerMixin作为基类,就可以免费获得fit_transform():默认实现将只调用fit(),然后再调用transform()。如果将BaseEstimator添加为基类(并避免使用*args和**kwargs),您还将获得两个额外的方法:get_params ()和set_params()。这些对于自动超参数调优非常有用。
例如,这里有一个自定义 transformer,其行为与StandardScaler非常相似:
from sklearn.base import BaseEstimator, TransformerMixinfrom sklearn.utils.validation import check_array, check_is_fittedclass StandardScalerClone (BaseEstimator, TransformerMixin ): def __init__ (self, with_mean=True ): self.with_mean = with_mean def fit (self, X, y=None ): X = check_array(X) self.mean_ = X.mean(axis=0 ) self.scale_ = X.std(axis=0 ) self.n_features_in_ = X.shape[1 ] return self def transform (self, X ): check_is_fitted(self) X = check_array(X) assert self.n_features_in_ == X.shape[1 ] if self.with_mean: X = X - self.mean_ return X / self.scale_
这里有几点需要注意:
sklearn.utils.validation 包含几个我们可以用来验证输入的函数。
Scikit-Learn管道要求fit()方法有两个参数X和y,这就是为什么我们需要y=None,即使我们不使用y。
所有Scikit-Learn估计器都在fit()方法中设置n_features_in_,并且它们确保传递给transform()或predict()的数据具有此数量的特征。
fit ()方法必须返回self。
(可选)所有的估算器都应该在拟合中设置 feature_names_in_()方法,它们被传递一个DataFrame。此外,所有的转换器都应该提供get_feature_names_out()方法。以及当它们的转换可以被逆转时的inverse_transform()方法。
TransformedTargetRegressor在拟合回归模型之前转换目标变量y,预测时则通过逆变换映射回原始值。它以回归估计器和将转换操作作为参数:
>>> import numpy as np>>> from sklearn.datasets import fetch_california_housing>>> from sklearn.compose import TransformedTargetRegressor>>> from sklearn.preprocessing import QuantileTransformer>>> from sklearn.linear_model import LinearRegression>>> from sklearn.model_selection import train_test_split>>> X, y = fetch_california_housing(return_X_y=True )>>> X, y = X[:2000 , :], y[:2000 ] >>> transformer = QuantileTransformer(output_distribution='normal' )>>> regressor = LinearRegression()>>> regr = TransformedTargetRegressor(regressor=regressor,... transformer=transformer)>>> X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0 )>>> regr.fit(X_train, y_train)TransformedTargetRegressor(...) >>> print ('R2 score: {0:.2f}' .format (regr.score(X_test, y_test)))R2 score: 0.61 >>> raw_target_regr = LinearRegression().fit(X_train, y_train)>>> print ('R2 score: {0:.2f}' .format (raw_target_regr.score(X_test, y_test)))R2 score: 0.59
对于简单的变换,可以传递变换和逆变换函数:
>>> def func (x ):... return np.log(x)>>> def inverse_func (x ):... return np.exp(x)>>> regr = TransformedTargetRegressor(regressor=regressor,... func=func,... inverse_func=inverse_func)>>> regr.fit(X_train, y_train)TransformedTargetRegressor(...) >>> print ('R2 score: {0:.2f}' .format (regr.score(X_test, y_test)))R2 score: 0.51
Pipeline允许按顺序将多个估计器连接成一个。这很有帮助,因为处理数据时通常有固定的步骤序列,例如特征选择、标准化和分类。Pipeline 只需在数据上调用拟合并预测一次,即可拟合整个估计器序列。
优秀的应用案例:机器学习之构建Pipeline(一) 机器学习之构建Pipeline(二)自定义Transformer和Pipeline 机器学习之构建Pipeline(三)从pipeline获取特征重要度
Pipeline 拟合数据,相当于依次对每个估计器拟合转换数据,且上一个估计器的输出作为下一个估计器的输入。因此,Pipeline 的中间步骤必须必须实现fit_transform和transform方法,最终估算器只需要实现fit。
Pipeline 具有最后一个估计器的所有方法。
sklearn.pipeline.Pipeline(steps, memory=None , verbose=False )
Pipeline使用(key,value)列表构建,其中key是名称字符串,value是估计器对象。Pipeline 中的估计器可以使用memory参数进行缓存。
>>> from sklearn.svm import SVC>>> from sklearn.preprocessing import StandardScaler>>> from sklearn.datasets import make_classification>>> from sklearn.pipeline import Pipeline>>> X, y = make_classification(random_state=0 )>>> X_train, X_test, y_train, y_test = train_test_split(X, y,... random_state=0 )>>> pipe = Pipeline([('scaler' , StandardScaler()), ('svc' , SVC())])>>> >>> >>> pipe.fit(X_train, y_train)>>> pipe.score(X_test, y_test)0.88
常用方法
说明
fit(X, y)
拟合模型
fit_predict(X, y)
转换数据,并调用最终估计器fit_predict方法
fit_transform(X, y)
拟合模型,并调用最终估计器transform方法
predict(X)
转换数据,并调用最终估计器的predict方法
predict_proba(X)
转换数据,并调用最终估计器的predict_proba方法
transform(X)
转换数据,并调用最终估计器的transform方法
get_feature_names_out()
获取/自定义切片估计器特征名称
get_params()
获得切片估计器的参数
set_params()
设置切片估计器的参数
管道的估计器作为列表存储在steps属性中
>>> pipe[:1 ]Pipeline(steps=[('scaler' , StandardScaler())]) >>> pipe[-1 :]Pipeline(steps=[('svc' , SVC())]) >>> pipe.steps[0 ]('scaler' , StandardScaler()) >>> pipe[0 ]PCA() >>> pipe['svc' ]PCA()
sklearn.pipeline.make_pipeline 是Pipeline 的快捷方式,依次传入估计器即可,不需要命名
>>> from sklearn.pipeline import make_pipeline>>> pipe = make_pipeline(StandardScaler(), SVC())
注意,make_pipeline并不是以列表的形式传入估计器
FeatureUnion将几个Transformer组合成一个新的Transformer。其中每个Transformer都独立并行拟合数据,然后将它们输出联合。
sklearn.pipeline.FeatureUnion(transformer_list, *, n_jobs=None , transformer_weights=None , verbose=False )
FeatureUnion使用(key,value)列表构建,其中key是名称字符串,value是估计器对象:
>>> from sklearn.pipeline import FeatureUnion>>> from sklearn.decomposition import PCA, TruncatedSVD>>> union = FeatureUnion([("pca" , PCA(n_components=1 )),... ("svd" , TruncatedSVD(n_components=2 ))])>>> X = [[0. , 1. , 3 ], [2. , 2. , 5 ]]>>> union.fit_transform(X)array([[ 1.5 , 3.0 ..., 0.8 ...], [-1.5 , 5.7 ..., -0.4 ...]]) >>> >>> union.set_params(svd__n_components=1 ).fit_transform(X)array([[ 1.5 , 3.0 ...], [-1.5 , 5.7 ...]])
许多数据集包含不同类型的特征,例如文本型、浮点型和日期型,其中每种类型的特征都需要单独的预处理或特征提取步骤。ColumnTransformer 对于每列,可以应用不同的变换,并且每个Transformer生成的特征将被连接起来,形成一个特征空间。
sklearn.compose.ColumnTransformer(transformers, *, remainder='drop' , sparse_threshold=0.3 , n_jobs=None ,transformer_weights=None , verbose=False , verbose_feature_names_out=True )
使用 (name, transformer, columns)列表构建,分别指定名称、Transformer对象和对应的特征名。
注意:转换特征矩阵中列的顺序遵循transformers列表中指定列的顺序。未指定的原始特征矩阵的列默认情况下(remainder='drop')将从生成的转换特征矩阵中删除,除非设置remainder='passthrough,那自动通过的列将被添加到transformers输出的末尾。如果remainder 是一个估计器,则剩余未指定的列使用remainder 估计器。
>>> import pandas as pd>>> X = pd.DataFrame(... {'city' : ['London' , 'London' , 'Paris' , 'Sallisaw' ],... 'title' : ["His Last Bow" , "How Watson Learned the Trick" ,... "A Moveable Feast" , "The Grapes of Wrath" ],... 'expert_rating' : [5 , 3 , 4 , 5 ],... 'user_rating' : [4 , 5 , 4 , 3 ]})>>> from sklearn.compose import ColumnTransformer>>> from sklearn.feature_extraction.text import CountVectorizer>>> from sklearn.preprocessing import OneHotEncoder>>> column_trans = ColumnTransformer(... [('categories' , OneHotEncoder(dtype='int' ), ['city' ]),... ('title_bow' , CountVectorizer(), 'title' )],... remainder='drop' , verbose_feature_names_out=False )>>> column_trans.fit(X)ColumnTransformer(transformers=[('categories' , OneHotEncoder(dtype='int' ), ['city' ]), ('title_bow' , CountVectorizer(), 'title' )], verbose_feature_names_out=False ) >>> column_trans.get_feature_names_out()array(['city_London' , 'city_Paris' , 'city_Sallisaw' , 'bow' , 'feast' , 'grapes' , 'his' , 'how' , 'last' , 'learned' , 'moveable' , 'of' , 'the' , 'trick' , 'watson' , 'wrath' ], ...) >>> column_trans.transform(X).toarray()array([[1 , 0 , 0 , 1 , 0 , 0 , 1 , 0 , 1 , 0 , 0 , 0 , 0 , 0 , 0 , 0 ], [1 , 0 , 0 , 0 , 0 , 0 , 0 , 1 , 0 , 1 , 0 , 0 , 1 , 1 , 1 , 0 ], [0 , 1 , 0 , 0 , 1 , 0 , 0 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 0 , 0 ], [0 , 0 , 1 , 0 , 0 , 1 , 0 , 0 , 0 , 0 , 0 , 1 , 1 , 0 , 0 , 1 ]]...)
我们在现实模型的训练过程中会有一些细节问题需要我们去解决。比如在很多流量很大的电商及资讯类网站的推荐系统中,每天的数据其实是增长很快的,所以模型迭代的频率也是非常高的;或者训练数据量太多的时候,模型有时候会出现Memory Error的错误。在这两种情况下,那么增量学习(incremental learning)就派上用场了。增量学习是近来才出现的概念,其目的在于训练数据的同时,也能保留以前模型的效果,即在之前模型的基础上对新增的数据进行训练,从而使模型能不断适应最新的数据。
sklearn中提供了很多增量学习算法。虽然不是所有的算法都可以增量学习,但是提供了 partial_fit 方法的估计器都可以进行增量学习。事实上,使用 mini-batch的数据进行增量学习是这些估计器的核心,因为它能让内存中始终只有少量的数据。
以下是不同任务的增量估计器列表:
Classification
sklearn.naive_bayes.MultinomialNB
sklearn.naive_bayes.BernoulliNB
sklearn.linear_model.Perceptron
sklearn.linear_model.SGDClassifier
sklearn.linear_model.PassiveAggressiveClassifier
sklearn.neural_network.MLPClassifier
Regression
sklearn.linear_model.SGDRegressor
sklearn.linear_model.PassiveAggressiveRegressor
sklearn.neural_network.MLPRegressor
Clustering
sklearn.cluster.MiniBatchKMeans
sklearn.cluster.Birch
Decomposition / feature Extraction
sklearn.decomposition.MiniBatchDictionaryLearning
sklearn.decomposition.IncrementalPCA
sklearn.decomposition.LatentDirichletAllocation
sklearn.decomposition.MiniBatchNMF
Preprocessing
sklearn.preprocessing.StandardScaler
sklearn.preprocessing.MinMaxScaler
sklearn.preprocessing.MaxAbsScaler
不同于使用fit方法,partial_fit 方法不需要清空模型,只需要每次传入mini-batch 数据,每个 batch 的数据的 shape 应保持一致。一般来说,在调用partial_fit时不应修改估计器参数。相比之下,warm_start常用于相同的数据使用不同的参数重复拟合。
在可迭代训练的模型中,partial_fit 方法通常是执行一次迭代。以 SGDClassifier 为例,增量学习流程如下
minibatch_iterators = get_minibatch(data, minibatch_size) cls = SGDClassifier() for i, (X_train, y_train) in enumerate (minibatch_iterators): cls.partial_fit(X_train, y_train) clf.score(X_test, y_test)
Example: 增量学习Demo之partial_fit 方法
warm_start 直译为热启动,在模型训练过程中起作用。如果 warm_start=True 就表示模型在重复调用 fit 方法时可以在前一阶段的训练结果上继续训练,而不清除原有模型,可以提升模型的训练速度,且训练结果保持一致。如果 warm_start=False 就表示从头开始训练模型。
在集成算法中,warm_start 将与 n_estimators交互。如果训练好了一个包含 n_estimators=N 个估计器的集成模型后,想在此基础上训练一个包含 n_estimators=M 个估计器的模型,则可以设置 warm_start=True,新模型在原有的基础上再训练 M-N 个新的估计器。
Example: 增量学习Demo之warm_start 参数
计算 sample_weight
from sklearn.utils.class_weight import compute_sample_weighty = [1 , 1 , 1 , 1 , 0 , 0 ] compute_sample_weight(class_weight="balanced" , y=y)
计算 class_weight
import numpy as npfrom sklearn.utils.class_weight import compute_class_weighty = [1 , 1 , 1 , 1 , 0 , 0 ] compute_class_weight(class_weight="balanced" , classes=np.unique(y), y=y)



 Give me money!
Give me money!









