Hadoop 简介
Apache Hadoop 是一种开源框架,用于高效存储和处理从 GB 级到 PB 级的大型数据集。利用 Hadoop,您可以将多台计算机组成集群以便更快地并行分析海量数据集,而不是使用一台大型计算机来存储和处理数据。
Hadoop 由四个主要模块组成:
-
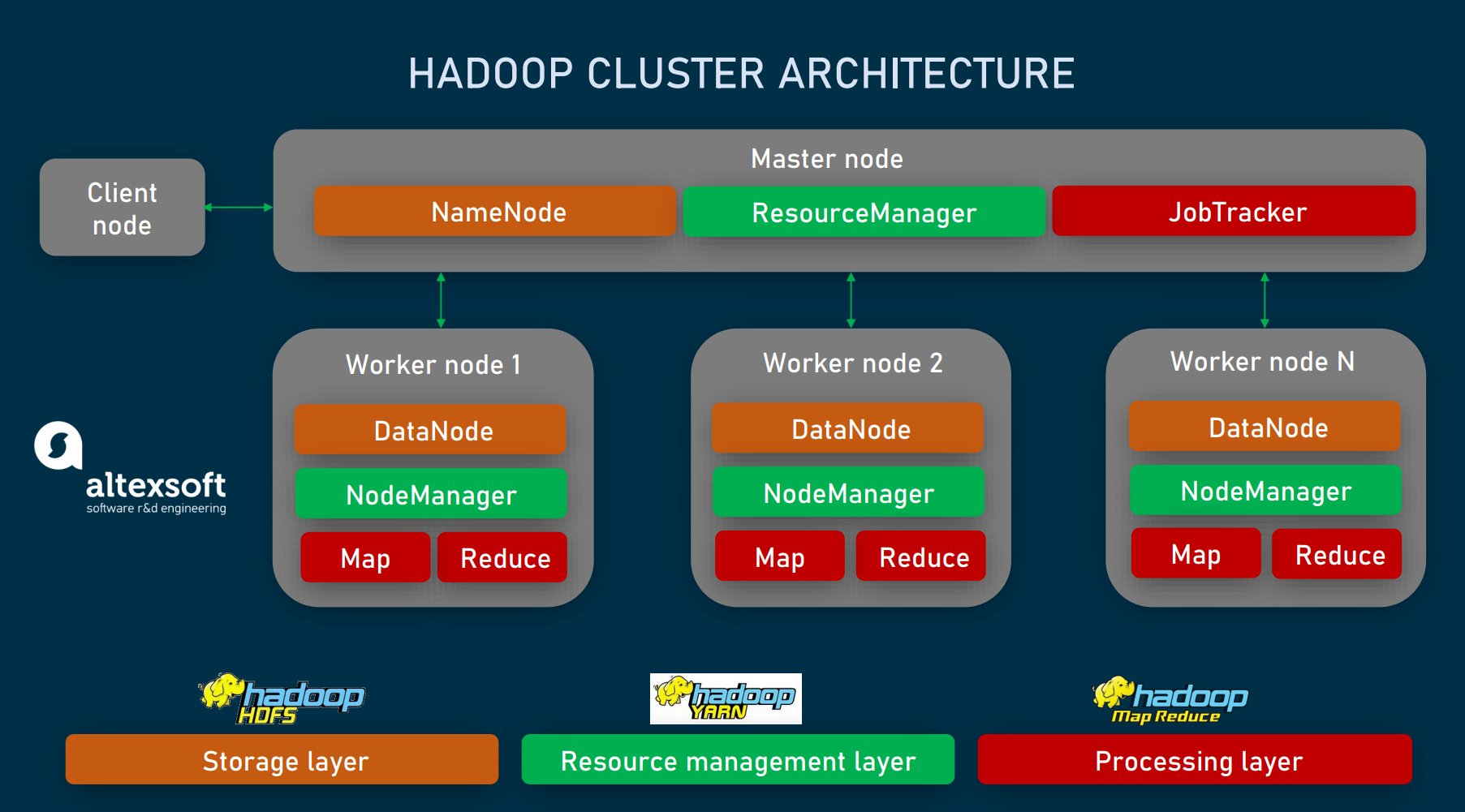
Hadoop 分布式文件系统 (HDFS)—一个在标准或低端硬件上运行的分布式文件系统。除了更高容错和原生支持大型数据集,HDFS 还提供比传统文件系统更出色的数据吞吐量。
-
Yet Another Resource Negotiator (YARN)—管理与监控集群节点和资源使用情况。它会对作业和任务进行安排。
-
MapReduce—一个帮助计划对数据运行并行计算的框架。该 Map 任务会提取输入数据,转换成能采用键值对形式对其进行计算的数据集。Reduce 任务会使用 Map 任务的输出来对输出进行汇总,并提供所需的结果。
-
Hadoop Common—提供可在所有模块上使用的常见 Java 库。
Hadoop 生态
Hadoop 让利用集群服务器中的全部存储和处理能力,针对大量数据执行分布式处理变得更简单。Hadoop 提供构建基块,然后在其上方构建其他服务和应用程序。
要收集各种格式数据的应用程序可以通过 API 操作连接到 NameNode,以便将数据放置到 Hadoop 集群当中。对于在 DataNodes 上重复的每个文件的“组块”,NameNode 会对它们的文件目录结构和位置进行追踪。要运行任务来查询数据,提供一个由众多 Map 和 Reduce 任务组成的 MapReduce 作业,而这些任务针对分散在 DataNodes 的 HDFS 中的数据运行。Map 任务在每个节点上针对提供的输入文件运行,而 Reduce 任务则会运行以汇总与整理最终的输出。
由于它的可延展性,Hadoop 生态系统多年来经历了迅猛发展。现在,Hadoop 生态系统包含众多工具和应用程序,可用来帮助收集、存储、处理、分析和管理大数据。

hadoop 常用命令
# Web UI available |
hdfs dfs -help # 查看帮助 |
 Give me money!
Give me money!










