Python 是一种易于学习又功能强大的编程语言。它提供了高效的高层次的数据结构,还有简单有效的面向对象编程。Python 优雅的语法和动态类型,以及解释型语言的本质,使它成为在很多领域多数平台上写脚本和快速开发应用的理想语言。
Python 简介
Python 是一种解释型、面向对象、动态数据类型的高级程序设计语言。
python 中万物皆对象。reset关键字或reset()函数可清空所有对象
help() 显示对象的帮助信息
调用解释器
有三种方式可以运行Python:
-
交互式解释器:你可以通过命令行窗口进入 Python,并在交互式解释器中开始编写 Python 代码。
$ python # Unix/Linux
-
执行脚本:在命令行中执行Python脚本
$ python script.py # Unix/Linux
-
IDE 中运行Python
在主提示符中,输入文件结束符(Unix 里是 Control-D,Windows 里是 Control-Z),就会退出解释器,退出状态码为 0。如果不能退出,还可以输入这个命令:quit()。
解释器的运行环境
对于大多数程序语言,第一个入门代码为例
#!/usr/bin/python |
-
解释器:关于脚本
#!行(首行)只对 Linux/Unix 用户适用,用来指定该脚本用什么解释器来执行。有这句的,可以直接用./执行。有两种写法:-
#!/usr/bin/python是告诉操作系统执行这个脚本的时候,调用 /usr/bin 下的 python 解释器。 -
#!/usr/bin/env python当系统看到这一行的时候,首先会到 env 设置里查找 python 的安装路径,再调用对应路径下的解释器程序完成操作。推荐这种写法,可以增强代码的可移植性。
调用 python 脚本时:
- 如果调用脚本时使用
python script.py第一行#!/usr/bin/python被忽略,等同于注释。 - 如果调用脚本时使用
./script.py第一行#!/usr/bin/python指定解释器的路径。
-
-
源文件的字符编码:Python 文件中如果未指定编码,在执行过程可能无法正确打印汉字。
在#!行(首行)后插入至少一行特殊的注释行来定义源文件的编码:
# -*- coding: UTF-8 -*-或者# coding=utf-8注意:
# coding=utf-8的 = 号两边不要空格。
行和缩进
学习 Python 与其他语言最大的区别就是,Python 的代码块不使用大括号 {} 来控制类,函数以及其他逻辑判断。python 最具特色的就是用缩进来写模块。
缩进的空白数量是可变的,但是所有代码块语句必须包含相同的缩进空白数量,这个必须严格执行。
Python 可以同一行显示多条语句,方法是用分号;分开,如:
$ print ('hello');print ('world'); |
Python语句中一般以新行作为语句的结束符。但是我们可以使用斜杠( \)将一行的语句分为多行显示
total = item_one + \ |
换行语句包含在 [], {}, () 中就不需要使用多行连接符。如下实例:
days = ['Monday', 'Tuesday', 'Wednesday', |
数据类型
数据类型
| 标量 | 说明 | 示例 |
|---|---|---|
| None | 空值 | 常常作为函数的默认参数 |
| str | 字符串 | 存有Unicode(UTF-8编码)字符串 |
| bytes | 原生ASCII字节 | |
| float | 浮点数 | 0.0 10.3e-3 |
| int | 整数 | 10 -0x260 (0x开头的为16进制数字) 0o69 (0o开头的为八进制) 0b1101 (0b开头的为二进制) |
| bool | 布尔型 | True/False |
| complex | 复数 | 3+2j complex(3,2) |
str, bool, int和float也是函数,可以用来转换类型
运算符
| 成员运算符 | 身份运算符 | 逻辑运算符 | 比较运算符 |
|---|---|---|---|
| in | is | and | >,< |
| not in | is not | or | >=,<= |
| not | != ,== |
2<3 and 'a'<'b' |
| 按位运算符 | 描述(二进制编码运算) | 实例a,b=60,13 |
|---|---|---|
| & | 按位与:参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0 | (a & b) 输出结果 12 ,二进制解释: 0000 1100 |
| | | 按位或运算符:只要对应的二个二进位有一个为1时,结果位就为1。 | (a | b) 输出结果 61 ,二进制解释: 0011 1101 |
| ^ | 按位异或运算符:当两对应的二进位相异时,结果为1 | (a ^ b) 输出结果 49 ,二进制解释: 0011 0001 |
| ~ | 按位取反运算符:对数据的每个二进制位取反,即把1变为0,把0变为1。~x 类似于 -x-1 | (~a ) 输出结果 -61 ,二进制解释: 1100 0011, 在一个有符号二进制数的补码形式。 |
| << | 左移动运算符:运算数的各二进位全部左移若干位,由"<<"右边的数指定移动的位数,高位丢弃,低位补0。 | a << 2 输出结果 240 ,二进制解释: 1111 0000 |
| >> | 右移动运算符:把">>“左边的运算数的各二进位全部右移若干位,”>>"右边的数指定移动的位数 | a >> 2 输出结果 15 ,二进制解释: 0000 1111 |
| 数学运算符 | 说明 |
|---|---|
** |
乘方 |
% |
求余数 |
// |
整除 |
+ |
合并str,tupple,list,数学加号 |
* |
重复str,tupple,list,数学乘号 |
- |
减号 |
/ |
除号 |
| 赋值运算符 | 描述 | 实例 |
|---|---|---|
= |
简单的赋值运算符 | c = a + b a=b=c=1 连续赋值 |
+= |
加法赋值运算符 | c += a 等效于 c = c + a |
-= |
减法赋值运算符 | c -= a 等效于 c = c - a |
*= |
乘法赋值运算符 | c *= a 等效于 c = c * a |
/= |
除法赋值运算符 | c /= a 等效于 c = c / a |
%= |
取模赋值运算符 | c %= a 等效于 c = c % a |
**= |
幂赋值运算符 | c **= a 等效于 c = c ** a |
//= |
取整除赋值运算符 | c //= a 等效于 c = c // a |
字符串
| 字符串 | 说明 |
|---|---|
| 单引号 | word = ‘字符串’ |
| 双引号 | sentence = “这是一个句子” |
| 三引号 | 字符串换行 |
| r’\n strings’ | \可以用来转义,前面加 r(raw) 则不发生转义 |
| u’中文字符’ | 中文常加u(unicode)前缀编译 |
string[start:end:step] |
切片(左闭右开区间) |
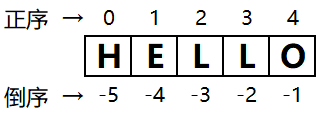
-
字符串文本能够分成多行。一种方法是使用三引号:
"""..."""或者'''...'''。行尾换行符会被自动包含到字符串中,但是可以在行尾加上\来避免这个行为。print("""\
Usage: thingy [OPTIONS]
-h Display this usage message
-H hostname Hostname to connect to
""")
Usage: thingy [OPTIONS]
-h Display this usage message
-H hostname Hostname to connect to -
相邻的两个字符串文本自动连接在一起,它只用于两个字符串文本,不能用于字符串表达式。这个功能在你想切分很长的字符串的时候特别有用。
text = ('Put several strings within parentheses '
'to have them joined together.')
text
'Put several strings within parentheses to have them joined together.'
元祖
元组是一个固定长度,不可改变的Python序列对象。元组由多个用逗号隔开的值组成,创建元组用括号 () 或 tuple(iterable)函数。
- 创建tuple
tup = (4, 5, 6), (7, 8) |
- 拆分元祖
tup = 4,5,(6,7) |
- 星号的使用:
*代表剩余部分
values = 94, 85, 73, 46 |
注意上面用星号解压出的变量永远都是列表类型。
- 元祖数学运算
tup1=(1,2,3) |
- 索引和切片
tup[index]
tup[start:stop:step] - 方法
tup.count(value)统计元组中某元素的个数
tup.index(value)元素第一次出现的索引位置
列表
创建列表用中括号 [] 或 list(iterable)函数。
- 创建list
a = [2, 3, 7, None] |
- 列表数学运算:同元组
- 索引和切片
list[index] # 索引 |
| 方法 | 说明 |
|---|---|
list.count(x) |
统计列表中某元素的个数 |
list.index(x,start,end) |
元素第一次出现的索引位置 |
list.append(x) |
向列表尾部追加一个新元素,只占一个索引位 |
list.extend(iterator) |
向列表尾部追加多个元素,将迭代器中的每个元素都追加进来 |
list.insert(index,x) |
指定位置插入元素 |
list.pop(index) |
删除并返回指定位置元素,默认最后一个元素 |
list.clear() |
清空列表,相当于 del a[:] |
list.remove(x) |
寻找第一个值并除去 |
list.copy() |
列表浅复制,相当于 a[:] |
list.reverse() |
反转列表 |
list.sort(*,key=None,reverse=False) |
将list中的元素升序排列 |
a=[1,2] |
字典
可以把字典理解为 key-value 的集合,但字典的键必须是唯一的。字典的值可以是任意Python对象,而键通常是不可变的标量类型(整数、浮点型、字符串)或元组(元组中的对象必须是不可变的),这被称为可哈希性。
创建字典可以用花括号 {'key1':value1,'key2':value2, ...} 或 dict(**kwargs)函数。花括号 {} 或 dict() 用于创建空字典。
创建dict(哈希映射或关联数组)
{'key1':value1,'key2':value2, ...} # 由key-value对创建 |
d['key'] # 访问dict元素 |
| 方法 | 说明 |
|---|---|
| dict.copy() | 浅复制 |
| dict.pop(key,default=None) | 删除并返回对应valueret = d.pop('a') |
| dict.popitem() | 随机返回并删除字典中的一对键和值(一般删除末尾对) |
| dict.clear() | 删除所有元素 |
| dict.update(dict2) | 将dict2中元素融入dict |
| dict.keys() | 返回keys迭代器 |
| dict.values() | 返回values迭代器 |
| dict.items() | 返回dict中所有的(key,val)元祖数组 |
| dict.get(key,default=None) | 如果key存在,返回value,否则返回default |
| dict.setdefault(key, default=None) | 如果键不存在于字典中,将会添加键并将值设为默认值。 |
# 对字典进行排序 |
集合
Python 还支持集合这种数据类型。集合是由不重复元素组成的无序容器。基本用法包括成员检测、消除重复元素。集合对象支持合集、交集、差集、对称差分等数学运算。
创建集合用花括号 {} 或 set(iterator)函数。注意,创建空集合只能用 set()。
{1,2,3} == {3,2,1} |
创建set
a = {1, 2, 3, 4, 5} |
| 方法 | 说明 | 替代语法 |
|---|---|---|
| set.add(value) | 将value添加到a | |
| set.remove(value) | 寻找第一个值并除去,不存在会报错 | |
| set.discard(value) | 删除集合中指定的元素,不会报错 | |
| set.copy() | 浅复制 | |
| set.pop(index) | 删除并返回指定位置元素 | |
| set.clear() | 清空a | |
| set.update(b) | 将b中元素融入a | a\=b |
| set.union(b) | 并集 | a|b |
| set.intersection(b) | 交集 | a&b |
| set.difference(b) | 差集(存在于a,不存在于b) | a-b |
| set.issubset(b) | if a∈b return True | |
| set.issuperset(b) | if b∈a return True | |
| set.isdisjoint(b) | if (交集) return True |
迭代器
迭代器 (iterator) 是一个可以记住遍历的位置的对象。字符串,列表或元组对象都可用iter()函数创建迭代器。
iterator = iter([1,2,3,4]) |
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
迭代器对象可以使用常规for语句进行遍历:
for i in iterator: |
也可以使用 next() 函数返回下一个迭代器对象:
while True: |
next() 函数在完成指定循环次数后触发 StopIteration 异常来结束迭代,防止出现无限循环的情况。
生成器
生成器 (generator):在 Python 中,使用了 yield 的函数被称为生成器,生成器是一个返回迭代器的函数,只能用于迭代操作。生成器函数可以逐步产生值,而不需要一次性计算并返回所有结果。
def squares(n=10): |
流程控制
if 语句
if 语句包含零个或多个 elif 子句,及可选的 else 子句。可以把 if ... elif ... elif ... 序列看作是其他语言中 switch 或 case 语句的替代品。
if expression: |
if 语句变体
# 利用list索引判断 |
三元表达式
value=true-expr if condition else false-expr |
for 循环
Python 的 for 语句迭代列表或字符串等任意序列,元素的迭代顺序与在序列中出现的顺序一致
for value in collection: |
while 循环
while expression: |
关键字
| 关键字 | 说明 |
|---|---|
pass |
占位 |
break |
用于跳出最近的 for 或 while 循环 |
continue |
跳出本次循环 |
match 语句
Python3.10 引入match 语句,接受一个表达式并将它的值与以一个或多个 case 语句块形式给出的一系列模式进行比较。
match expression: |
最简单的形式是将一个目标值与一个或多个字面值进行比较:
def http_error(status): |
请注意最后一个代码块: “变量名” _ 被作为 通配符 并必定会匹配成功。 如果没有任何 case 语句匹配成功,则任何分支都不会被执行。
你可以使用 | (“ or ”)在一个模式中组合几个字面值:
case 401 | 403 | 404: |
推导式
list_comp = [expr for value in collection if condition] |
内置函数
常用函数
globals()和 locals() 函数可被用来返回全局和局部命名空间里的名字。
| 输入输出 | |
|---|---|
| input(prompt=None) | 输入 |
| print(value, …, sep=’ ‘, end=’\n’, file=sys.stdout, flush=False) | 输出 |
| 数学函数 | |
|---|---|
| round(number, ndigits=None) | 四舍五入 |
| abs(x) | |
| len(obj) | 序列元素数 |
| max(obj) | |
| min(obj) | |
| pow(base, exp, mod=None) | |
| divmod(a,b) | 返回元组(a // b, a % b) |
| hex(x) | 10进制转16进制,以字符表示(0x开头的格式,如0x10) |
| int(x, base=10) | 用于将一个字符串或数字转换为整型,默认十进制 |
| oct(x) | 将一个整数转换成8进制字符串 |
| bin(x) | 返回一个整数 int 或者长整数 long int 的二进制表示 |
| complex(real, imag) | 返回复数 |
| hash(object) | 获取哈希值 |
| 面向对象 | |
|---|---|
| type(obj) | 输出对象类型 |
| dir(object) | 输出对象属性和方法 |
| isinstance(obj,class_or_tuple) | 判断对象类型(‘int’, ‘str’,’ list’…) |
| setattr(object, name, value) | 设置对象属性 |
| getattr(object, name[, default]) | 返回一个对象属性值 |
| hasattr(object, name) | 判断对象是否包含对应的属性 |
| delattr(object, name) | 删除属性 |
| issubclass(class, classinfo) | 判断是否子类 |
| vars([object]) | 函数返回对象object的属性和属性值的字典对象 |
| 字符表达式 | 说明 |
|---|---|
| eval(expression) | 执行一个字符串表达式,并返回表达式的值eval('pow(2,2)') |
| exec(object) | 执行复杂的表达式,返回None |
x = 10 |
| 内建函数 | 说明 |
|---|---|
| chr() | 把编码转换为对应的字符 |
| id([object]) | 获取对象内存地址 |
| iter(object[, sentinel]) | 生成迭代器 |
| all(iterable) | 给定的可迭代对象全部为True,类似于and |
| any(iterable) | 给定的可迭代对象任一为True,类似于or |
| reversed(seq) | 反转序列,返回迭代器 |
| callable(object) | 判断对象是否是可调用,对于函数, 方法, lambda 函式, 类, 以及实现了 __call__方法的类实例, 它都返回 True |
高阶函数
| 高阶函数 | 说明 |
|---|---|
| map(function,obj) | 对序列中所有元素函数映射 |
| reduce(function, iterable[, initializer]) | 对参数序列中元素进行累积 python3从内置模块移除 from functools import reduce |
| filter(function, iterable) | 返回一个迭代器 |
strings = ['a','as','bat','car','dove','python'] |
序列函数
enumerate函数,可以返回(i, value)元组序列,常用于loop:
for i, value in enumerate(collection): |
sorted函数
sorted(list) 返回排序好的list副本
sorted(str) 拆分str,返回排序好的list副本
sorted 也可使用 key 参数对字典进行排序
In [150]: d = {'a':3, 'b':2, 'c':1} |
zip函数
zip(seq1,seq2) 可以将多个列表、元组或其它序列成对组合成一个元组对
zip可以处理任意多的序列,元素的个数取决于最短的序列
zip(*tup)逆转用法
In [89]: seq1 = ['foo', 'bar', 'baz'] |
排列,组合,笛卡儿积
from itertools import product,permutations,combinations
参考链接:https://blog.csdn.net/specter11235/article/details/71189486
range函数
range(start=0,end,step=1) 返回一个迭代器,它产生一个均匀分布的整数序列 [start,end) by step
自定义函数
函数语法
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号
()。 - 圆括号之间可以用于定义参数。
- 函数内容以冒号起始,并且缩进。
- 函数的第一行语句可以选择性地使用文档字符串用于存放函数说明。
return关键字结束函数,返回函数值。不带表达式的return相当于返回 None。
def area(a, b): |
通常,函数的一半代码行是文档。编写适当的文档字符串不仅对其他人理解我们的代码至关重要,而且当我们回看它时,我们可以理解自己的代码!
参数顺序
def fun(var1, var2=default, *args, **kwargs): |
参数顺序:必选参数>默认参数>可变参数>关键字参数
在Python中,*args 和 **kwargs 是用来处理可变数量的参数的特殊符号。它们允许函数接受任意数量的位置参数和关键字参数,使得函数更加灵活。
- 参数
*args用于接收可变数量的参数,可以将多个参数打包成元组传递给函数 - 参数
**kwargs用于接收可变数量的key-word参数,可以将多个key-word参数打包成字典传递给函数
通过示例演示如何使用这两种特殊参数,以及如何在函数中处理和打印这些参数。
def test(a,*args, b, **kwargs): |
可变参数之后的参数必须指定参数名,否则都会被归到可变参数之中。关键字参数都只能作为最后一个参数。
函数参数拆包
Python中可以在函数参数中使用星号(*)拆包列表、元祖和字典
例如,自定义函数
def mySum(a, b): |
单个星号解压列表元组
m = (1, 2) |
两个星号解压字典
mydict = {'a':1, 'b': 2} |
函数注解
我们知道 Python 是一种动态语言,变量以及函数的参数是不区分类型的。
Python解释器会在运行的时候动态判断变量和参数的类型,这样的好处是编写代码速度很快,很灵活,但是坏处也很明显,不好维护,可能代码写过一段时间重新看就很难理解了,因为那些变量、参数、函数返回值的类型,全都给忘记了。
所以Python3里有了这个新特性,可以给参数、函数返回值和变量的类型加上注解,不过这个仅仅是注释而已,对代码的运行来说没有任何影响,变量的真正类型还是会有Python解释器来确定,你所做的只是在提高代码的可读性,让 IDE 了解类型,从而提供更准确的代码提示、补全和语法检查,仅此而已。
注解是以字典形式存储在函数的 __annotations__属性中,对函数的其它部分没有任何影响。
def add(x:int, y:int) -> int: |
变量的作用域
Python中变量的作用域一共有4种,分别是:
- L (Local) 局部作用域
- E (Enclosing) 闭包函数外的函数中
- G (Global) 全局作用域
- B (Built-in) 内建作用域
以 L –> E –> G –>B 的规则查找,即:在局部找不到,便会去局部外的局部找(例如闭包),再找不到就会去全局找,再者去内建中找。
x = int(2.9) # 内建作用域 |
Python 中只有模块(module),类(class)以及函数(def、lambda)才会引入新的作用域,其它的代码块(如 if/elif/else/、try/except、for/while等)是不会引入新的作用域的,也就是说这些语句内定义的变量,外部也可以访问。
局域变量和全局变量
当内部作用域想修改外部作用域的变量时,就要用到global和nonlocal关键字了
num=1 |
lambda 函数
lambda 函数不用写return,返回值就是该表达式的结果
lambda vars : expr |
例如
add = lambda x,y : x+y |
闭包
def print_msg(): |
一般情况下,函数中的局部变量仅在函数的执行期间可用,一旦 print_msg() 执行过后,我们会认为 msg变量将不再可用。然而,在这里我们发现 print_msg 执行完之后,在调用 another 的时候 msg 变量的值正常输出了,这就是闭包的作用,闭包使得局部变量在函数外被访问成为可能。
看完这个例子,我们再来定义闭包,维基百科上的解释是:
在计算机科学中,闭包(Closure)是词法闭包(Lexical Closure)的简称,是引用了自由变量的函数。这个被引用的自由变量将和这个函数一同存在,即使已经离开了创造它的环境也不例外。所以,有另一种说法认为闭包是由函数和与其相关的引用环境组合而成的实体。
这里的 another 就是一个闭包,闭包本质上是一个函数,它由两部分组成,printer 函数和变量 msg。闭包使得这些变量的值始终保存在内存中。
装饰器
装饰器实际上是在不改变原程序的情况下,给某程序增添功能,避免大量雷同代码。
菜鸟教程(包括带参数的装饰器和装饰器类等)
http://www.runoob.com/w3cnote/python-func-decorators.html
参考文档:http://lib.csdn.net/article/python/62942
from functools import wraps |
错误和异常处理
捕获异常
异常捕捉可以使用 try-except 语句
try: |
try-except 语句按照如下方式工作:
-
首先,执行 try 子句(在 try 和 except 关键字之间的语句)
- 如果没有异常发生, except 子句 在 try 语句执行完毕后就被忽略了
- 如果在 try 子句执行过程中发生了异常,那么该子句其余的部分就会被忽略
-
如果异常匹配于 except 关键字后面指定的异常类型,就执行对应的except子句。然后继续执行 try 语句之后的代码。
-
如果发生了一个异常,在 except 子句中没有与之匹配的分支,它就会传递到上一级 try 语句中
-
如果最终仍找不到对应的处理语句,它就成为一个 未处理异常,终止程序运行,显示提示信息。
-
一个
try-except语句可能包含多个 except 子句,分别指定处理不同的异常。至多只会有一个分支被执行。 -
一个except子句可以同时处理多个异常,这些异常将被放在一个括号里成为一个元组,例如:
except (RuntimeError, TypeError, NameError):
pass -
最后一个except子句可以忽略异常的名称,它将被当作通配符使用。你可以使用这种方法打印一个错误信息,然后再次把异常抛出。
-
-
try-except语句还有一个可选的 else 子句,如果使用这个子句,那么必须放在所有的 except 子句之后。else 子句将在 try 子句没有发生任何异常的时候执行。 -
finally 语句无论是否发生异常都将执行最后的代码
import sys |
抛出异常
raise 语句允许程序员强制抛出一个指定的异常
raise [expression [from expression]] |
- 如果不带表达式,raise 会重新抛出当前作用域内最后一个激活的异常。 如果当前作用域内没有激活的异常,将会引发
RuntimeError来提示错误。 - raise 的第一个表达式必需是一个异常实例或异常类(继承自
BaseException的子类或示例)。
raise NameError('HiThere') |
模块管理
在Python中,每个脚本都可以作为一个单独的脚本进行运行,也可以作为一个模块被其他脚本引入。
pip
pip 是一个现代的,通用的 Python 包管理工具。提供了对 Python 包的查找、下载、安装、卸载的功能。pip 已内置于 Python 3.4 和 2.7 及以上版本,其他版本需另行安装。
| shell 命令 | 说明 |
|---|---|
| pip install package_name | 导入包 |
| pip install --upgrade package_name | 更新包 |
| pip uninstall package_name | 卸载包 |
| pip list | 列出已安装的包 |
| pip show package_name | 显示包的信息,包括安装路径 |
添加镜像源 vim ~.pip/pip.conf
[global] |
# 指定版本安装 |
conda
Miniconda是一款小巧的python环境管理工具,安装包大约只有50M多点,其安装程序中包含conda软件包管理器和Python。一旦安装了Miniconda,就可以使用conda命令安装任何其他软件工具包并创建环境等。
下载安装
wget -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-latest-Linux-x86_64.sh |
添加镜像源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free |
| shell 命令 | 说明 |
|---|---|
| conda list | 查看已经安装的包 |
| conda install package_name | 导入包 |
| conda update package_name | 更新包 |
| conda remove package_name | 删除包 |
| conda search package_name | 查找package信息 |
conda将conda、python等都视为package
更新conda |
模块路径
当你导入一个模块,Python 解析器对模块位置的搜索顺序是:
- 当前目录
- 如果不在当前目录,Python 则搜索在 shell 变量 PYTHONPATH 下的每个目录。
- 如果都找不到,Python会察看默认路径。UNIX下,默认路径一般为/usr/local/lib/python/。
模块搜索路径存储在 system 模块的 sys.path 变量中。变量里包含当前目录,PYTHONPATH和由安装过程决定的默认目录。
# pip 命令显示包的信息,包括安装路径 |
如果包不在管理路径下,可以在python环境变量中增加包的安装路径,也能正常加载
例如想在默认python中加载pyspark包,则将pyspark路径加载到python环境变量中 |
加载模块
以 numpy 包为例
# 导入整个模块 |
一个模块只会被导入一次,不管你执行了多少次import。这样可以防止导入模块被一遍又一遍地执行。
因此,如果你想重新执行模块里顶层部分的代码,可以用 reload() 函数。该函数会重新导入之前导入过的模块。语法如下:
reload(numpy) |
__name__ 变量
在Python中经常会看到 if __name__ == '__main__' 这行代码,它的作用是判断当前脚本是被直接执行还是作为模块被导入。通过判断__name__变量的取值,可以确定当前的执行情况。这样可以确保测试代码只在直接执行脚本时被执行,而在导入为模块时不被执行。
 Give me money!
Give me money!








